
Auto Scaling Group in AWS Chuyên mục EC2 Service - Elastic Load Balancing & Auto Scaling Group 2024-04-27 62 Lượt xem 59 Lượt thích 0 Bình luận Sidebar
Auto Scaling Group
Auto Scaling Group (ASG) là một dịch vụ của Amazon Web Services (AWS) cho phép tự động điều chỉnh số lượng và kích thước của các instance EC2 trong một nhóm dựa trên các quy tắc được định cấu hình trước. Mục tiêu chính của ASG là đảm bảo rằng ứng dụng của bạn luôn có số lượng instance đủ để xử lý tải và đảm bảo sự ổn định và hiệu suất của hệ thống.
Các điểm chính của Auto Scaling Group bao gồm:
-
Tự Động Mở Rộng và Thu Nhỏ: ASG tự động tăng hoặc giảm số lượng các instance EC2 trong nhóm dựa trên các chỉ số như tải CPU, lưu lượng mạng, hoặc các metric do người dùng định cấu hình.
-
Load Balancer Integration: ASG tích hợp chặt chẽ với các dịch vụ load balancer của AWS như ELB (Elastic Load Balancer), cho phép tự động thêm và xóa các instance từ load balancer khi chúng được thêm hoặc loại bỏ khỏi nhóm.
-
Khả Năng Mở Rộng Theo Dung Lượng: Bạn có thể định cấu hình ASG để tự động mở rộng theo dung lượng, tức là tăng số lượng instance khi một tham số như lượng lưu lượng mạng vượt quá một ngưỡng được xác định.
-
Fault Tolerance(Khả năng chịu lỗi): ASG giúp đảm bảo tính sẵn sàng cao của hệ thống bằng cách tự động thay thế các instance bị lỗi bằng các instance mới.
-
Chi Phí Hiệu Quả: Sử dụng ASG giúp tối ưu hóa chi phí bằng cách tự động thu nhỏ số lượng instance trong nhóm khi không cần thiết, giảm chi phí phát sinh từ việc duy trì các instance không sử dụng.
Tóm lại, Auto Scaling Group là một công cụ quan trọng trong việc tối ưu hóa việc quản lý và vận hành hạ tầng điện toán đám mây trên AWS, giúp bạn đảm bảo sự ổn định, linh hoạt và chi phí hiệu quả cho ứng dụng của mình.
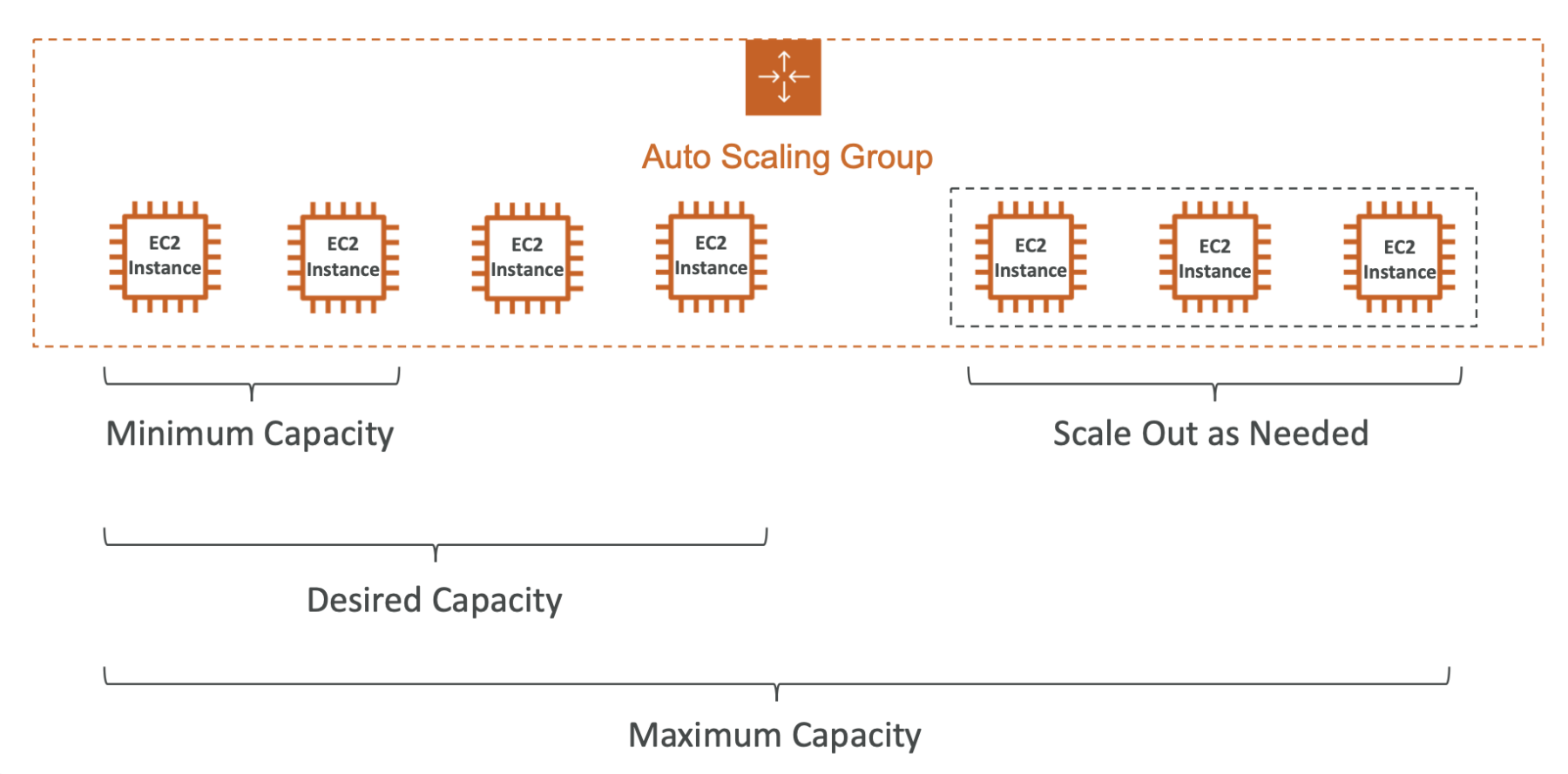
Auto Scaling Group in AWS With Load Balancer
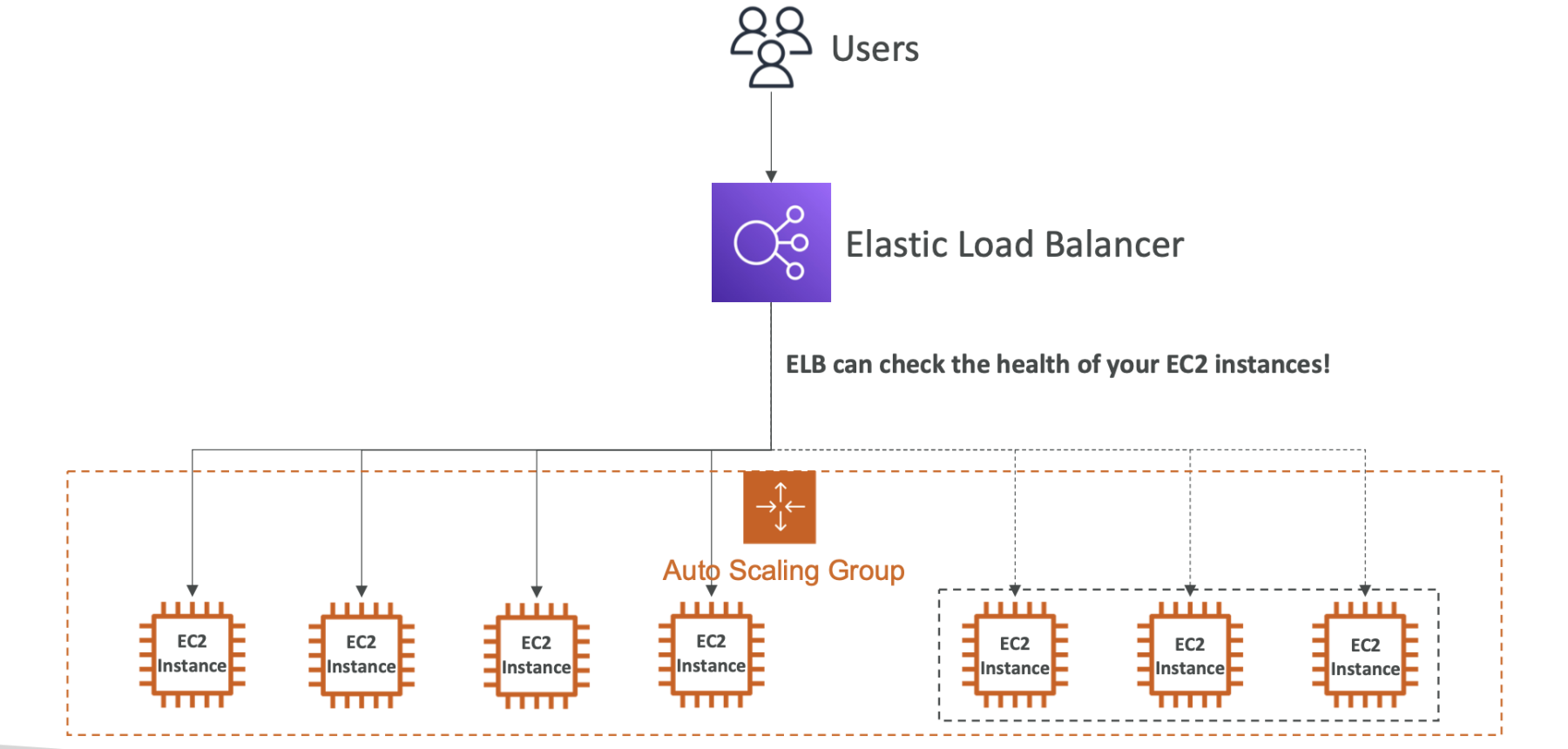
Khi sử dụng Auto Scaling Group (ASG), bạn có thể định cấu hình tự động tăng hoặc giảm số lượng các instance EC2 trong nhóm dựa trên các quy tắc như tải CPU, lưu lượng mạng hoặc các metric do người dùng định cấu hình. Điều này giúp đảm bảo rằng ứng dụng của bạn luôn có đủ khả năng chịu tải và duy trì hiệu suất ổn định.
Khi kết hợp với dịch vụ Load Balancer, ASG có thể tự động thêm các instance mới vào load balancer khi chúng được khởi chạy và sẵn sàng phục vụ traffic, cũng như tự động loại bỏ các instance không còn hoạt động khỏi load balancer khi chúng bị loại bỏ khỏi nhóm.
"Auto Scaling Group in AWS With Load Balancer" chỉ ra một chiến lược tự động hóa quản lý và mở rộng hạ tầng trên AWS bằng cách sử dụng cả hai dịch vụ ASG và Load Balancer để đảm bảo hiệu suất và sẵn sàng cao cho ứng dụng của bạn.
Auto Scaling Group Attributes

-
Launch Template (Launch Configurations đã bị deprecated):
- Một launch template được sử dụng để định cấu hình các chi tiết của các instance mới sẽ được khởi chạy khi Auto Scaling Group tạo ra các instance mới.
- Launch template bao gồm thông tin như AMI (Amazon Machine Image), loại instance, user data, và các thông số khác như volume, network, IAM role, và security groups.
-
EC2 User Data:
- Dữ liệu người dùng được gắn vào instance khi chúng được khởi chạy, thường được sử dụng để thực hiện các hành động tùy chỉnh như cài đặt và cấu hình phần mềm.
-
EBS Volumes:
- Cấu hình về các EBS volumes (Elastic Block Store) được gắn vào các instance, bao gồm thông tin về kích thước, loại, và các thuộc tính khác của volume.
-
Security Groups:
- Các nhóm bảo mật (security groups) được áp dụng cho các instance, quy định các luật truy cập mạng và bảo mật.
-
SSH Key Pair:
- Cặp khóa SSH được sử dụng để truy cập vào các instance thông qua SSH.
-
IAM Roles for your EC2 Instances:
- Các vai trò IAM được gán cho các instance, cho phép các instance truy cập vào các dịch vụ AWS mà không cần sử dụng thông tin xác thực tĩnh như Access Key ID và Secret Access Key.
-
Network + Subnets Information:
- Thông tin về mạng và các subnet mà các instance được đặt vào.
-
Load Balancer Information:
- Thông tin về các load balancer mà các instance được đăng ký và mà traffic được phân phối qua.
-
Min Size / Max Size / Initial Capacity:
- Số lượng instance tối thiểu (Min Size), tối đa (Max Size), và khởi tạo ban đầu (Initial Capacity) trong nhóm.
-
Scaling Policies:
- Các chính sách tự động mở rộng hoặc thu nhỏ kích thước của nhóm dựa trên các metric như tải CPU, lưu lượng mạng, hoặc số lượng requests.
Tóm lại, các thuộc tính này đóng vai trò quan trọng trong việc xác định cấu hình và hành vi của Auto Scaling Group, giúp đảm bảo sự linh hoạt, hiệu suất và sẵn sàng của hạ tầng của bạn trên AWS.
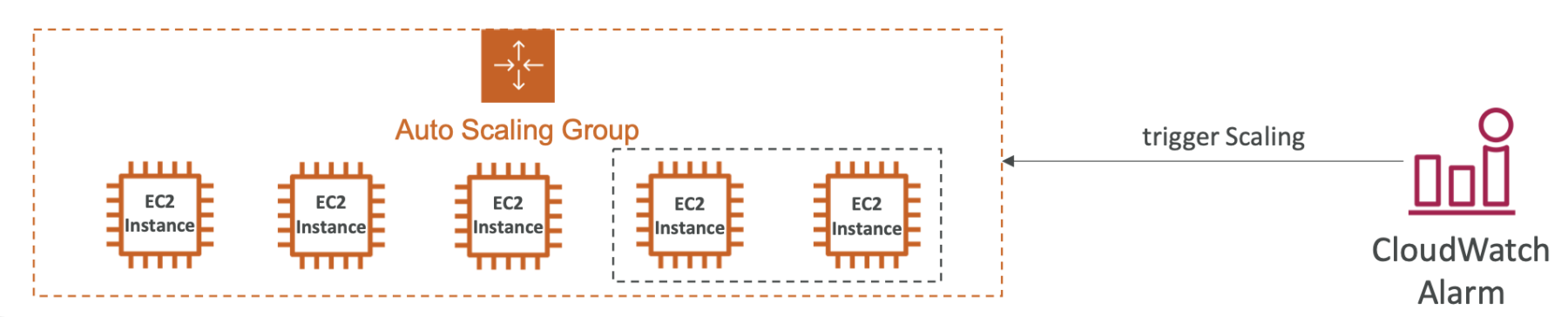
Auto Scaling - CloudWatch Alarms & Scaling
Chúng ta có thể tự động mở rộng hoặc thu nhỏ một nhóm Auto Scaling dựa trên các cảnh báo từ CloudWatch.
-
Có thể tự động mở rộng một Auto Scaling Group dựa trên CloudWatch alarms:
- Điều này có nghĩa là bạn có thể định cấu hình các cảnh báo trong CloudWatch để theo dõi các metric như tải CPU trung bình hoặc các metric tùy chỉnh khác, và tự động mở rộng hoặc thu nhỏ số lượng instance trong nhóm Auto Scaling dựa trên các điều kiện này.
-
Một cảnh báo giám sát một metric (như CPU trung bình hoặc một metric tùy chỉnh):
- CloudWatch cung cấp các cảnh báo để giám sát các metric, và bạn có thể định cấu hình các cảnh báo này để theo dõi các biểu đồ và thông báo bạn khi giá trị metric vượt quá hoặc dưới một ngưỡng nhất định.
-
Các metric như CPU trung bình được tính toán cho toàn bộ các instance trong nhóm Auto Scaling:
- Khi bạn định cấu hình một cảnh báo CloudWatch để giám sát một metric như CPU, giá trị trung bình của metric này được tính toán cho tất cả các instance trong nhóm Auto Scaling.
-
Dựa trên cảnh báo:
- Dựa trên cảnh báo từ CloudWatch, bạn có thể tạo các chính sách tự động mở rộng (scale-out policies) để tăng số lượng instance khi tải lên, và tạo các chính sách tự động thu nhỏ (scale-in policies) để giảm số lượng instance khi tải xuống.
Bên trên là mô tả cách mà chúng ta có thể sử dụng CloudWatch alarms để tự động điều chỉnh kích thước của một nhóm Auto Scaling dựa trên các metric giám sát, như tải CPU, giúp đảm bảo sự linh hoạt và hiệu suất của hạ tầng điện toán của bạn trên AWS.
Auto Scaling Groups – Dynamic Scaling Policies
Auto Scaling, các loại chính sách tự động mở rộng (Dynamic Scaling Policies) được mô tả như sau:
-
Target Tracking Scaling:
- Loại chính sách này là cách đơn giản và dễ dàng để thiết lập.
- Ví dụ: Bạn muốn trung bình CPU của Auto Scaling Group (ASG) duy trì ở mức khoảng 40%. Khi tải CPU tăng, ASG sẽ tự động tăng hoặc giảm số lượng các instance để duy trì trung bình CPU ở mức được đặt ra.
-
Simple / Step Scaling:
- Khi một báo động CloudWatch được kích hoạt (ví dụ: CPU > 70%), sau đó thêm 2 đơn vị.
- Khi một báo động CloudWatch được kích hoạt (ví dụ: CPU < 30%), sau đó loại bỏ 1 đơn vị.
- Đây là một phương pháp linh hoạt hơn, cho phép bạn định cấu hình các bước cụ thể cho việc tăng hoặc giảm kích thước của nhóm.
-
Scheduled Actions:
- Loại chính sách này cho phép dự đoán các hoạt động mở rộng dựa trên các mẫu sử dụng đã biết.
- Ví dụ: Tăng khả năng tối thiểu lên 10 vào lúc 5 giờ chiều vào các thứ Sáu hàng tuần, dựa trên mẫu sử dụng đã biết vào thời điểm đó.
Các Dynamic Scaling Policies mở rộng này trong Auto Scaling cho phép chúng ta tùy chỉnh cách mà nhóm của bạn tự động mở rộng hoặc thu nhỏ dựa trên các điều kiện và quy tắc đã được định cấu hình, giúp đảm bảo rằng hệ thống của bạn luôn linh hoạt và sẵn sàng đối mặt với các biến động trong tải.
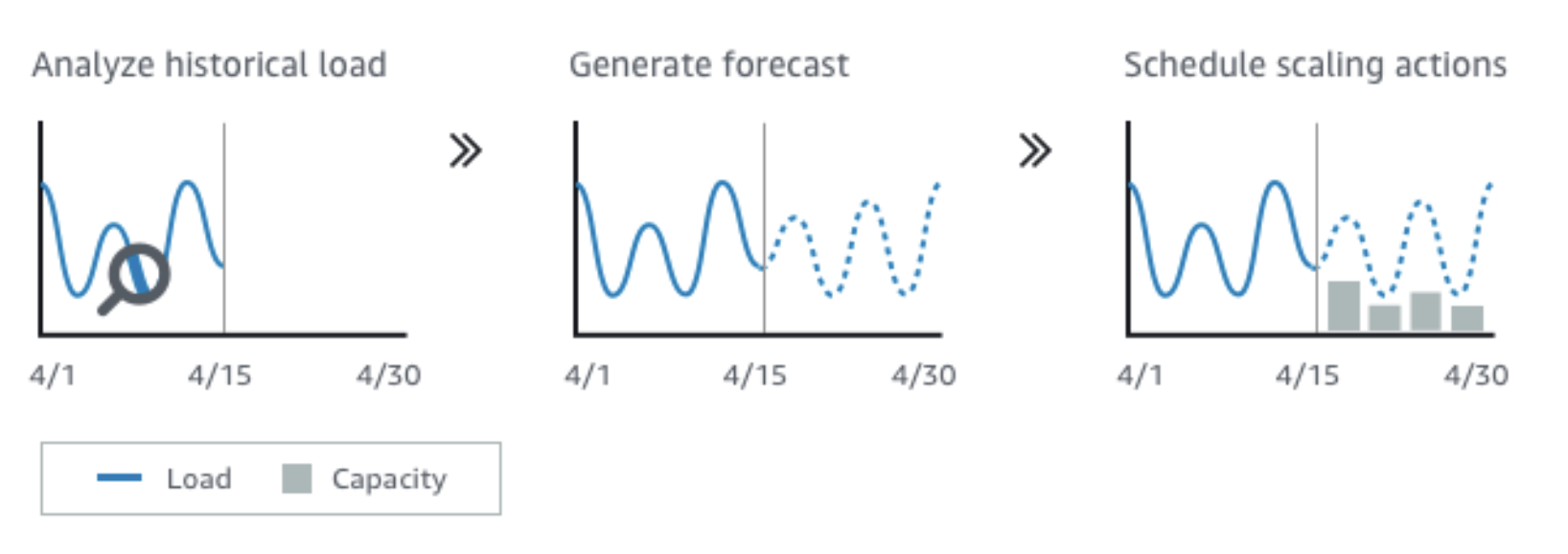
Auto Scaling Groups – Predictive Scaling
"Predictive Scaling" là một tính năng mới được giới thiệu để cải thiện quá trình tự động mở rộng của Auto Scaling Groups bằng cách dự đoán tải và lên lịch mở rộng trước.
Cụ thể, "Predictive Scaling" cho phép Auto Scaling Group dự đoán và dự báo tải của hệ thống dựa trên các mẫu tải trước đó và các xu hướng trong dữ liệu lịch sử. Dựa trên dự đoán này, Auto Scaling Group có thể lên lịch mở rộng hoặc thu nhỏ kích thước của nhóm trước khi tải thực sự tăng hoặc giảm, giúp tránh được các đợt tăng tải đột ngột và giảm thiểu thời gian cần thiết để phản ứng.
Tính năng này có thể giúp cải thiện hiệu suất và sự ổn định của hệ thống bằng cách giảm thiểu thời gian đáp ứng và đảm bảo rằng hệ thống luôn có đủ tài nguyên để xử lý tải, đồng thời giảm thiểu việc sử dụng tài nguyên không cần thiết trong những thời điểm tải thấp.
Auto Scaling Groups - Scaling Cooldowns
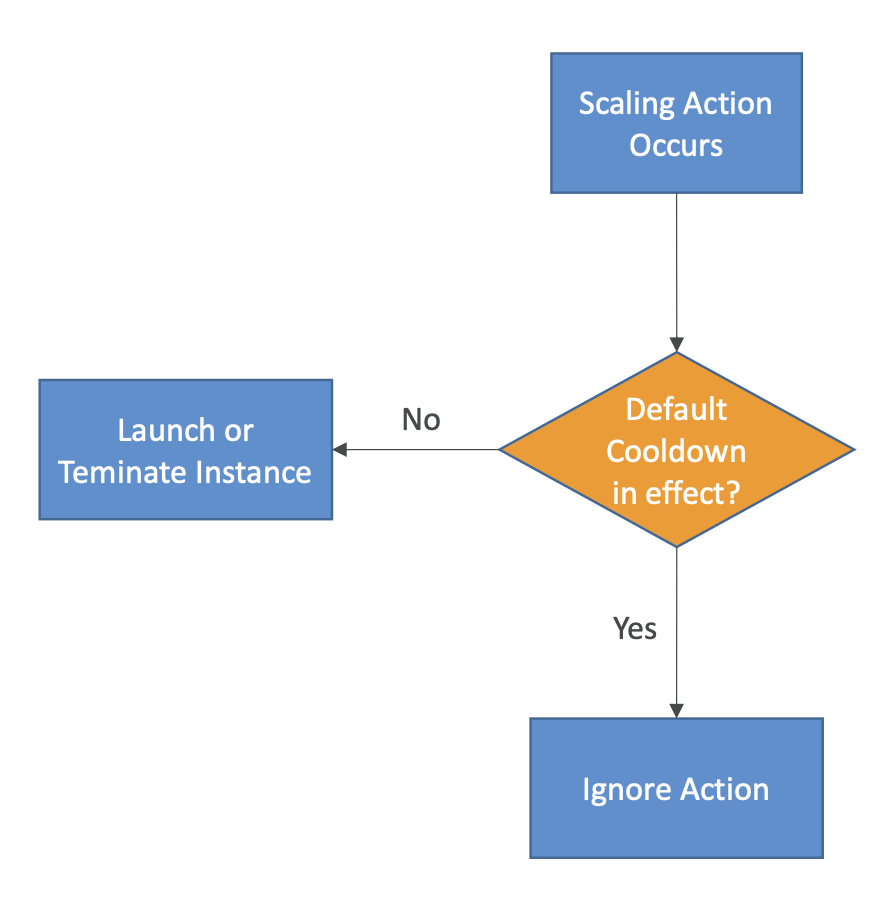
"Scaling Cooldowns" và cách chúng hoạt động trong quá trình tự động mở rộng của Auto Scaling Group (ASG). Dưới đây là ý nghĩa của nó:
-
After a scaling activity happens, you are in the cooldown period (default 300 seconds):
- Sau khi một hoạt động mở rộng hoặc thu nhỏ xảy ra trong Auto Scaling Group (ASG), hệ thống sẽ chuyển sang giai đoạn cooldown (thời gian làm mát).
- Thời gian cooldown mặc định là 300 giây, tức là sau khi một hoạt động scaling xảy ra, ASG sẽ chờ trong 300 giây trước khi tiến hành hoạt động scaling tiếp theo.
-
During the cooldown period, the ASG will not launch or terminate additional instances (to allow for metrics to stabilize):
- Trong thời gian cooldown, ASG sẽ không khởi chạy hoặc chấm dứt các instance mới (launch) hoặc cũ (terminate) để cho phép các metric ổn định.
- Điều này giúp đảm bảo rằng các metric như tải CPU, lưu lượng mạng, hoặc số lượng request đã ổn định trước khi ASG tiến hành hoạt động mở rộng hoặc thu nhỏ tiếp theo.
-
Advice: Use a ready-to-use AMI to reduce configuration time in order to be serving requests faster and reduce the cooldown period:
- Lời khuyên: Sử dụng một AMI sẵn có để giảm thời gian cấu hình, từ đó giúp phục vụ các yêu cầu (requests) nhanh hơn và giảm thời gian cooldown.
- Sử dụng một AMI sẵn có thay vì tự tạo AMI từ đầu giúp tiết kiệm thời gian cấu hình, từ đó giảm thời gian cooldown và cho phép ASG phản ứng nhanh chóng khi có yêu cầu tăng cường khối lượng công việc.
Các dòng trên giải thích về thời gian cooldown và cách hoạt động của nó trong quá trình tự động mở rộng của Auto Scaling Group, cùng với lời khuyên về việc sử dụng AMI sẵn có để giảm thời gian cấu hình và tăng cường khả năng phục vụ của hệ thống.
Instance Management
-
Warm pool trong Auto Scaling Group (ASG):
- Warm pool trong ASG là một nhóm các instances (máy ảo) đã được khởi động và sẵn sàng hoạt động, nhưng chưa tham gia vào việc xử lý tải công việc.
- Mục đích chính của warm pool là để giảm thời gian khởi tạo mới khi cần mở rộng, bằng cách giữ các instances sẵn sàng để kích hoạt ngay lập tức thay vì phải chờ đợi quá trình khởi tạo mới.
- Warm pool thường được sử dụng trong các tình huống mà thời gian đáp ứng nhanh là quan trọng, hoặc khi cần đảm bảo sự liên tục và sẵn sàng của hệ thống.
- Bạn cần thủ công thêm các instances từ Warm pool vào target group của bạn để chúng nhận lưu lượng truy cập.
-
Tối ưu thời gian đáp ứng: Bằng cách duy trì các instances sẵn sàng trong Warm pool, hệ thống của bạn có thể đáp ứng nhanh chóng và không bị trễ khi có lưu lượng truy cập đột ngột hoặc tăng cao.
-
Đảm bảo sẵn sàng và tin cậy: Warm pool giúp đảm bảo rằng các instances được chuẩn bị trước và sẵn sàng hoạt động khi cần thiết, giảm thiểu thời gian gián đoạn và đảm bảo sự tin cậy của hệ thống.
-
Xử lý tình huống khẩn cấp: Trong những tình huống khẩn cấp, ví dụ như một instance gặp sự cố hoặc một tăng đột ngột trong lưu lượng truy cập, Warm pool cung cấp một giải pháp tức thì để mở rộng và duy trì sự ổn định của hệ thống.
-
Tối ưu hóa hiệu suất: Bằng cách sử dụng Warm pool, bạn có thể tối ưu hóa hiệu suất của hệ thống bằng cách giảm thiểu thời gian khởi động mới và tăng khả năng đáp ứng của hệ thống.
-
-
ASG lifecycle hook:
- ASG lifecycle hook là một tính năng của Auto Scaling Group (ASG) trong AWS, cho phép bạn thực hiện các hành động cụ thể trước và sau khi các instances được thêm vào hoặc loại bỏ khỏi ASG.
- Mục đích chính của ASG lifecycle hook là kiểm soát quá trình thêm mới và loại bỏ instances từ ASG, cho phép bạn thực hiện các hành động như chuẩn bị, kiểm tra, hoặc thực hiện xử lý sau khi các instances được thêm hoặc loại bỏ.
- Lifecycle hook có thể được kích hoạt khi một instance được thêm vào (scaling out) hoặc được loại bỏ (scaling in) từ ASG. Khi một lifecycle hook được kích hoạt, ASG sẽ tạm dừng quá trình và chờ đợi sự xác nhận từ bạn (hoặc từ hệ thống của bạn) trước khi tiếp tục.
- Lifecycle hook cung cấp một cơ chế linh hoạt để kiểm soát quá trình thêm mới và loại bỏ instances từ ASG, giúp bạn có thể thực hiện các hành động cụ thể trước và sau các sự kiện quan trọng như thêm mới instance hoặc loại bỏ instance.
-
Giả sử bạn có một ứng dụng web đang chạy trên các instances EC2 được quản lý bởi một ASG. Khi một instance mới được thêm vào ASG để mở rộng, bạn muốn kiểm tra xem nó đã sẵn sàng để xử lý lưu lượng hoặc không. Bạn sử dụng lifecycle hook để thực hiện kiểm tra này trước khi ASG tiếp tục với quá trình thêm mới instance.
-
Abandon:
- Trong trường hợp này, nếu ASG không nhận được thông báo xác nhận từ bạn trong khoảng thời gian timeout, nó sẽ bỏ qua lifecycle hook và tiếp tục với quá trình thêm mới hoặc xoá instance như một cách bình thường.
- Ví dụ: Nếu ASG không nhận được phản hồi từ bạn trong vòng 5 phút sau khi kích hoạt lifecycle hook, nó sẽ bỏ qua lifecycle hook và tiếp tục với quá trình thêm mới instance mà không kiểm tra xem instance đã sẵn sàng hoặc không.
-
Continue:
- Trong trường hợp này, nếu ASG không nhận được thông báo xác nhận từ bạn trong khoảng thời gian timeout, nó vẫn tiếp tục với quá trình thêm mới instance nhưng không hoàn tất nó. Điều này có nghĩa là ASG không thực hiện bất kỳ hành động nào khác sau khi timeout xảy ra, và bạn cần phải xác định cụ thể hành động tiếp theo. Nhưng không hoàn tất nó có nghĩa là:
- Instance không được tính vào tổng số instance hiện có của ASG
- Instance không được đưa vào sử dụng
- Instance vẫn tồn tại nhưng không được sử dụng
- Ví dụ: Nếu ASG không nhận được phản hồi từ bạn trong vòng 5 phút sau khi kích hoạt lifecycle hook, nó sẽ vẫn tiếp tục với quá trình thêm mới instance, nhưng không thực hiện bất kỳ hành động nào khác. Bạn có thể tiếp tục kiểm tra instance sau hoặc thực hiện các biện pháp khắc phục nếu cần.
- Trong trường hợp này, nếu ASG không nhận được thông báo xác nhận từ bạn trong khoảng thời gian timeout, nó vẫn tiếp tục với quá trình thêm mới instance nhưng không hoàn tất nó. Điều này có nghĩa là ASG không thực hiện bất kỳ hành động nào khác sau khi timeout xảy ra, và bạn cần phải xác định cụ thể hành động tiếp theo. Nhưng không hoàn tất nó có nghĩa là:
-
- Cách xác nhận được thực hiện thông qua việc gửi phản hồi cho ASG thông qua các công cụ như Amazon SNS hoặc Amazon EventBridge. Bạn có thể cấu hình ASG để tiếp tục hoặc bỏ qua quá trình dựa trên phản hồi bạn cung cấp. Điều này cho phép bạn kiểm soát và can thiệp vào quá trình mở rộng tự động của hệ thống của mình, đảm bảo rằng mọi thay đổi đều được kiểm soát và xác nhận trước khi áp dụng.
Good metrics to scale on
Dưới đây là mô tả các metric được sử dụng để định cấu hình các chính sách tự động mở rộng hoặc thu nhỏ kích thước của nhóm dựa trên các điều kiện nhất định. Dưới đây là ý nghĩa của mỗi metric:
-
CPUUtilization:
- Đây là metric dùng để đo lường tỷ lệ sử dụng CPU trung bình trên các instance trong nhóm. Nếu CPUUtilization cao, điều này có thể cho thấy rằng các instance đang hoạt động gần tới giới hạn sức chứa của chúng và cần tăng cường thêm instance để phân phối tải.
-
RequestCountPerTarget:
- Metric này đo lường số lượng yêu cầu trung bình được gửi đến mỗi instance EC2 trong nhóm. Nếu số lượng yêu cầu per instance không ổn định, có thể cần điều chỉnh kích thước của nhóm để đảm bảo mỗi instance không bị quá tải hoặc bỏ trống.
-
Average Network In / Out:
- Các metric này đo lường lưu lượng mạng trung bình vào và ra khỏi các instance trong nhóm. Nếu ứng dụng của bạn có xu hướng mạng đặc biệt lớn và lưu lượng mạng tiêu thụ quá nhiều tài nguyên, có thể cần điều chỉnh kích thước của nhóm để đảm bảo hiệu suất mạng.
-
Any custom metric (that you push using CloudWatch):
- Bạn cũng có thể sử dụng bất kỳ metric tùy chỉnh nào mà bạn định nghĩa và đẩy lên CloudWatch. Điều này cho phép bạn theo dõi và đánh giá các yếu tố cụ thể của ứng dụng của bạn, như số lượng người dùng đồng thời, dung lượng bộ nhớ sử dụng, hoặc bất kỳ thông tin nào khác quan trọng cho việc quyết định mở rộng hoặc thu nhỏ kích thước của nhóm.
Tóm lại, các metric này cung cấp thông tin quan trọng về hiệu suất và tải của các instance trong nhóm, giúp Auto Scaling tự động điều chỉnh kích thước của nhóm để đảm bảo sự ổn định và hiệu suất của hệ thống.
Thực Hành
| Attributes | Chức năng |
|---|---|
| Launch template | Định nghĩa các cài đặt cho các instance mới trong Auto Scaling Group, bao gồm AMI, instance type, key pair, user data, và các cài đặt khác. |
| Network | Xác định mạng (VPC) và các khu vực khả dụng và các subnet mà các instance sẽ được triển khai vào. |
| - VPC | Chọn mạng ảo riêng (VPC) mà Auto Scaling Group sẽ sử dụng. |
| - Availability Zones and subnets | Chọn các khu vực và các subnet trong VPC mà các instance sẽ được triển khai vào. |
| Load balancing | Quyết định cách Auto Scaling Group sẽ được kết nối với các Load Balancer. |
| - No load balancer | Không sử dụng Load Balancer. |
| - Attach to an existing load balancer | Kết nối Auto Scaling Group với một Load Balancer đã tồn tại trong tài khoản AWS. |
| - Attach to a new load balancer | Tạo một Load Balancer mới và kết nối Auto Scaling Group với nó. |
| VPC Lattice integration options | Tùy chọn tích hợp với dịch vụ mạng Lattice trong VPC. |
| - No VPC Lattice service | Không tích hợp với dịch vụ mạng Lattice. |
| - Attach to VPC Lattice service | Tích hợp với dịch vụ mạng Lattice trong VPC. |
| Health checks (EC2 health checks) | Quyết định cách Auto Scaling Group kiểm tra sức khỏe của các instance. |
| - Turn on Elastic Load Balancing health checks | Sử dụng các kiểm tra sức khỏe của Elastic Load Balancer để xác định sự khỏe mạnh của các instance. |
| - Turn on VPC Lattice health checks | Sử dụng các kiểm tra sức khỏe do dịch vụ mạng Lattice trong VPC cung cấp. |
| - Health check grace period | Thiết lập thời gian mà Auto Scaling Group sẽ đợi trước khi bắt đầu kiểm tra sức khỏe của các instance mới được triển khai. |
| Additional settings | Các cài đặt bổ sung cho Auto Scaling Group. |
| - Enable group metrics collection within CloudWatch | Cho phép thu thập các số liệu về hiệu suất và hoạt động của Auto Scaling Group trong Amazon CloudWatch. |
| - Enable default instance warmup | Thiết lập thời gian mà các instance mới được triển khai phải chờ trước khi nhận được lưu lượng truy cập. |
| Group size | Xác định số lượng instance mong muốn trong Auto Scaling Group. |
| - Desired capacity | Số lượng instance mà bạn muốn có trong Auto Scaling Group. |
| Scaling (Scaling limits) | Đặt giới hạn về quy mô của Auto Scaling Group. |
| - Min desired capacity | Số lượng tối thiểu của instance mà Auto Scaling Group sẽ duy trì. |
| - Max desired capacity | Số lượng tối đa của instance mà Auto Scaling Group có thể tạo ra. |
| Automatic scaling - optional | Quyết định cách Auto Scaling Group tự động mở rộng hoặc thu hẹp dựa trên các ngưỡng được đặt ra. |
| - No scaling policies | Không có chính sách tự động mở rộng hoặc thu hẹp. |
| - Target tracking scaling policy | Chính sách tự động mở rộng hoặc thu hẹp dựa trên một mục tiêu xác định như CPU utilization hoặc số lượng yêu cầu trên giây. |
| Instance maintenance policy | Quyết định cách Auto Scaling Group xử lý các trường hợp bảo trì instance. |
| - No policy | Không có chính sách cụ thể cho việc maintain instance. |
| - Launch before terminating | Triển khai một instance mới trước khi hủy bỏ instance cũ. |
| - Terminate and launch | Hủy bỏ instance cũ và sau đó triển khai một instance mới. |
| - Custom behavior | Xác định các hành vi tùy chỉnh cho việc triển khai và hủy bỏ instance. |
Target tracking scaling policy
Target tracking scaling policy có thể sử dụng một số loại Metric type để quản lý tự động quy mô của Auto Scaling Group. Dưới đây là các loại Metric type phổ biến và cách hoạt động của từng loại:
-
CPU utilization:
- Metric: CPU utilization là tỷ lệ phần trăm thời gian mà CPU của các instance trong Auto Scaling Group được sử dụng trong một khoảng thời gian nhất định.
- Cách hoạt động: Khi sử dụng CPU utilization làm Metric type, bạn thiết lập một mức đích CPU utilization nhất định. Auto Scaling Group sẽ tự động điều chỉnh số lượng instance để đảm bảo rằng CPU utilization trên các instance đạt mức mục tiêu.
- Ví dụ: Bạn thiết lập một mức đích CPU utilization là 70%. Khi CPU utilization trên các instance vượt quá 70%, Auto Scaling Group sẽ tự động tăng số lượng instance. Ngược lại, nếu CPU utilization thấp hơn 70%, Auto Scaling Group sẽ giảm số lượng instance.
- Test:
-
sudo amazon-linux-extras install epel -y sudo yum install stress -y stress --cpu 8 --timeout 300s
-
-
Request count per target:
- Metric: Số lượng yêu cầu mà mỗi instance trong Auto Scaling Group nhận được trong một khoảng thời gian nhất định.
- Cách hoạt động: Bạn thiết lập một mức đích số lượng yêu cầu mỗi giây mà mỗi instance trong Auto Scaling Group nên xử lý. Auto Scaling Group sẽ tự động điều chỉnh số lượng instance để đảm bảo rằng số lượng yêu cầu trên mỗi instance đạt mức mục tiêu.
- Ví dụ: Bạn thiết lập một mức đích là 1000 yêu cầu mỗi giây cho mỗi instance. Khi số lượng yêu cầu vượt quá 1000 yêu cầu mỗi giây trên mỗi instance, Auto Scaling Group sẽ tự động tăng số lượng instance. Ngược lại, nếu số lượng yêu cầu thấp hơn 1000 yêu cầu mỗi giây, Auto Scaling Group sẽ giảm số lượng instance.
-
Average network in:
- Metric: Lưu lượng mạng trung bình vào (network in) trên mỗi instance trong Auto Scaling Group trong một khoảng thời gian nhất định.
- Cách hoạt động: Bạn thiết lập một mức đích cho lưu lượng mạng trung bình vào mà mỗi instance trong Auto Scaling Group nên xử lý. Auto Scaling Group sẽ tự động điều chỉnh số lượng instance để đảm bảo rằng lưu lượng mạng trung bình vào trên mỗi instance đạt mức mục tiêu.
- Ví dụ: Bạn thiết lập một mức đích là 100 MB/giờ cho lưu lượng mạng trung bình vào mỗi instance. Khi lưu lượng mạng trung bình vào vượt quá 100 MB/giờ trên mỗi instance, Auto Scaling Group sẽ tự động tăng số lượng instance. Ngược lại, nếu lưu lượng mạng trung bình vào thấp hơn 100 MB/giờ, Auto Scaling Group sẽ giảm số lượng instance.
-
Average network out:
- Metric: Lưu lượng mạng trung bình ra (network out) từ mỗi instance trong Auto Scaling Group trong một khoảng thời gian nhất định.
- Cách hoạt động: Bạn thiết lập một mức đích cho lưu lượng mạng trung bình ra mà mỗi instance trong Auto Scaling Group nên tạo ra. Auto Scaling Group sẽ tự động điều chỉnh số lượng instance để đảm bảo rằng lưu lượng mạng trung bình ra từ mỗi instance đạt mức mục tiêu.
- Ví dụ: Bạn thiết lập một mức đích là 50 MB/giờ cho lưu lượng mạng trung bình ra từ mỗi instance. Khi lưu lượng mạng trung bình ra vượt quá 50 MB/giờ từ mỗi instance, Auto Scaling Group sẽ tự động tăng số lượng instance. Ngược lại, nếu lưu lượng mạng trung bình ra thấp hơn 50 MB/giờ, Auto Scaling Group sẽ giảm số lượng instance.
Step Scaling Policy
- Step scaling cho phép bạn định nghĩa các quy tắc tăng hoặc giảm kích thước của ASG dựa trên giá trị các metric được thu thập từ Amazon CloudWatch.
- Bạn có thể định nghĩa các bước tăng hoặc giảm kích thước ASG khi giá trị của metric vượt qua một ngưỡng nhất định.
- Ví dụ: Nếu giá trị của CPU utilization vượt qua ngưỡng 70% trong 5 phút, thì tăng kích thước ASG lên 1 instance. Nếu giảm xuống dưới 30% trong 10 phút, thì giảm kích thước ASG đi 1 instance.
Simple Scaling Policy
- Simple scaling là phương pháp đơn giản hơn, cho phép bạn chỉ định một ngưỡng trên và dưới cho một metric cụ thể.
- Khi giá trị của metric vượt qua ngưỡng trên, ASG sẽ tăng kích thước. Khi giá trị của metric giảm xuống dưới ngưỡng dưới, ASG sẽ giảm kích thước.
- Ví dụ: Nếu giá trị của số lượng yêu cầu tăng lên trên 1000 trong 5 phút, tăng kích thước ASG lên 2 instances. Nếu giảm xuống dưới 500 trong 10 phút, giảm kích thước ASG đi 1 instance.
Có thể bạn chưa biết?
1.Disable scale in to create only a scale-out policy
"Disable scale in to create only a scale-out policy" có nghĩa là bạn đã tắt chức năng tự động thu nhỏ (scale in) của Auto Scaling Group và chỉ tạo ra các chính sách mở rộng (scale-out).
Khi bạn tắt chức năng này, ASG sẽ không tự động giảm số lượng instances khi lưu lượng giảm đi hoặc khi mức sử dụng tài nguyên (ví dụ: CPU) của các instances hiện tại thấp hơn ngưỡng cấu hình. Thay vào đó, nó sẽ chỉ triển khai các instances mới khi cần thiết để đáp ứng nhu cầu lưu lượng truy cập.
Với cấu hình này, ASG chỉ thực hiện các hành động mở rộng (scale-out), nghĩa là nó chỉ triển khai thêm các instances mới khi lưu lượng truy cập tăng cao hoặc khi các instances hiện tại gặp vấn đề hoặc quá tải. Các instances mới này có thể được triển khai từ Warm pool hoặc được khởi động từ zero.
Bằng cách tắt chức năng scale in, bạn có thể kiểm soát hơn quá trình mở rộng của hệ thống và tránh việc loại bỏ instances mà bạn không muốn trong một số trường hợp cụ thể. Tuy nhiên, điều này cũng có thể dẫn đến sự lãng phí tài nguyên nếu số lượng instances không được điều chỉnh tự động theo nhu cầu thực tế của ứng dụng.
2. Instance draining, instance warm-up, và scaling cooldowns
Instance draining, instance warm-up, và scaling cooldowns là ba khái niệm quan trọng trong quá trình quản lý và mở rộng tự động của hệ thống sử dụng Auto Scaling Group (ASG) trên AWS. Dưới đây là sự so sánh giữa ba khái niệm này:
-
Instance Draining:
- Mục đích: Instance draining là quá trình loại bỏ instances từ service load balancer một cách an toàn trước khi chúng bị loại bỏ khỏi ASG. Quá trình này đảm bảo rằng các instances không nhận thêm lưu lượng truy cập mới trước khi chúng được loại bỏ, đồng thời đảm bảo rằng các kết nối hiện có vẫn được xử lý.
- Cách hoạt động: Khi một instance được đánh dấu để bị loại bỏ, service load balancer sẽ chuyển hướng lưu lượng truy cập ra khỏi instance đó, sau đó ASG sẽ chờ đợi cho đến khi tất cả các kết nối hiện có đã được xử lý xong trước khi loại bỏ instance.
- Ứng dụng: Instance draining đảm bảo rằng không có mất mát dữ liệu hoặc lưu lượng truy cập trong quá trình loại bỏ instances, giúp đảm bảo sự liên tục của dịch vụ.
-
Instance Warm-up:
- Mục đích: Instance warm-up là quá trình chuẩn bị và "thắng cảnh" các instances mới trước khi chúng được đưa vào dịch vụ và nhận lưu lượng truy cập.
- Cách hoạt động: Trong quá trình khởi động, ASG có thể cấu hình để chờ một khoảng thời gian warm-up trước khi bắt đầu kiểm tra sẵn sàng của instance mới. Trong khoảng thời gian này, các instance mới sẽ được chuẩn bị và cấu hình để đáp ứng với yêu cầu của dịch vụ.
- Ứng dụng: Instance warm-up giúp đảm bảo rằng các instances mới đã sẵn sàng và đạt được hiệu suất tối ưu trước khi nhận lưu lượng truy cập thực tế, giảm thiểu thời gian chờ đợi và đảm bảo sự ổn định của dịch vụ.
- Cũng cần lưu ý rằng việc thiết lập warm-up time có thể làm tăng thời gian mà ASG mất để thêm mới instance vào dịch vụ. Điều này có thể ảnh hưởng đến khả năng mở rộng nhanh chóng của hệ thống trong một số tình huống.
-
Scaling Cooldowns:
- Mục đích: Scaling cooldowns là khoảng thời gian mà ASG chờ đợi giữa các hoạt động mở rộng (scale-out) hoặc thu nhỏ (scale-in), để tránh việc mở rộng hoặc thu nhỏ quá nhanh và gây ra sự không ổn định.
- Cách hoạt động: Khi một hoạt động mở rộng hoặc thu nhỏ được kích hoạt, ASG sẽ chờ đợi cho đến khi khoảng thời gian cooldown đã qua trước khi thực hiện hoạt động mở rộng hoặc thu nhỏ tiếp theo.
- Ứng dụng: Scaling cooldowns giúp đảm bảo rằng ASG reaggrupulate sau mỗi thay đổi và tránh việc thực hiện các hoạt động mở rộng hoặc thu nhỏ liên tục, giúp ổn định hệ thống và tránh tình trạng quá tải hoặc sụp đổ.
- Được thiết lập trọng phần Advanced configurations
-
Health Check Grace Period:
- Mục đích: Health check grace period là thời gian mà ASG chờ đợi sau khi khởi động instance mới trước khi bắt đầu kiểm tra sức khỏe của chúng. Trong khoảng thời gian này, các instance mới được coi là "chưa sẵn sàng" và không được kiểm tra sức khỏe, dù chúng đã hoạt động.
- Cách hoạt động: Khi một instance mới được khởi động, ASG sẽ chờ đợi cho đến khi thời gian grace period đã qua trước khi bắt đầu kiểm tra sức khỏe của instance. Trong khoảng thời gian này, instance mới có thể hoạt động nhưng vẫn được coi là không sẵn sàng cho lưu lượng truy cập.
- Ứng dụng: Health check grace period giúp đảm bảo rằng các instance mới đã được triển khai và hoạt động một cách đầy đủ trước khi ASG bắt đầu kiểm tra sức khỏe của chúng. Điều này giúp tránh việc loại bỏ instances mới mà chưa hoàn toàn sẵn sàng, và giảm thiểu nguy cơ cho lưu lượng truy cập.
-
Maximum Instance Lifetime:
- Mục đích: Điều chỉnh tuổi thọ tối đa của các instances trong ASG để đảm bảo rằng chúng được thay thế định kỳ, giữ tính mới mẻ và bảo mật của hệ thống.
- Ứng dụng: Maximum instance lifetime đảm bảo rằng các instances không sử dụng quá lâu và được thay thế định kỳ, giúp tăng cường bảo mật, quản lý chi phí và tối ưu hóa hiệu suất của hệ thống.
Bình luận (0)