
Index trong SQL là gì và khi nào nên đánh index? Chuyên mục Bài Viết Hay 2024-01-05 151 Lượt xem 109 Lượt thích 0 Bình luận

Việc tạo và quản lý các chỉ số (index) trong cơ sở dữ liệu là một khía cạnh quan trọng của việc tối ưu hóa hiệu suất truy vấn. Index đóng vai trò như một bảng danh sách, giúp cơ sở dữ liệu nhanh chóng định vị và trả về dữ liệu cần thiết. Trong bài viết này, chúng ta sẽ thảo luận về các khái niệm cơ bản về index, tại sao chúng ta cần chúng, cách chúng hoạt động, cùng với các chiến lược và thủ thuật để sử dụng index hiệu quả.
Index là gì?
Trong ngữ cảnh của cơ sở dữ liệu, index là một cấu trúc dữ liệu được tạo ra từ một hoặc nhiều cột trong bảng để tăng tốc quá trình truy xuất dữ liệu. Index hoạt động như một chỉ mục, giúp cơ sở dữ liệu nhanh chóng định vị và trả về kết quả cho các truy vấn phổ biến.
Tạo Index như thế nào?
Trong SQL, việc tạo và sử dụng index là một phần quan trọng của việc tối ưu hóa hiệu suất truy vấn. Khi tạo index trong SQL, bạn chỉ định các cột trong bảng mà bạn muốn tạo index, và cơ sở dữ liệu sẽ tạo ra một cấu trúc dữ liệu bổ sung để tăng tốc độ truy vấn.
Để tạo index trong SQL, bạn sử dụng câu lệnh CREATE INDEX. Cú pháp cơ bản như sau:
CREATE INDEX index_name ON table_name (column1, column2, ...);Trong đó:
- index_name là tên của index bạn muốn tạo.
- table_name là tên của bảng mà index sẽ được tạo trên.
- (column1, column2, ...): là danh sách các cột trong bảng mà bạn muốn tạo index.
Tại sao cần sử dụng index?
Index giúp cải thiện hiệu suất truy vấn bằng cách giảm thời gian tìm kiếm dữ liệu. Khi không có index, cơ sở dữ liệu phải duyệt qua toàn bộ bảng để tìm kiếm các hàng phù hợp với điều kiện của truy vấn. Tuy nhiên, khi có index, cơ sở dữ liệu có thể sử dụng cấu trúc này để nhanh chóng định vị các hàng phù hợp, giảm thiểu thời gian và tài nguyên cần thiết cho việc truy vấn.
Cách hoạt động của index
Khi tạo index trên một cột, cơ sở dữ liệu sẽ tạo ra một cấu trúc dữ liệu bổ sung (thường là cây B-tree) để lưu trữ các giá trị của cột đó theo một cách tổ chức tối ưu. Khi thực hiện truy vấn, cơ sở dữ liệu sẽ sử dụng index này để nhanh chóng định vị các hàng chứa giá trị tương ứng.
Khi nào nên sử dụng index?
- Khi có nhu cầu truy vấn dữ liệu thường xuyên
- Nếu một cột thường xuyên được sử dụng trong các điều kiện truy vấn, việc tạo index trên cột đó có thể cải thiện đáng kể hiệu suất của các truy vấn.
-
Khi dữ liệu bảng lớn
- Trong các bảng có số lượng hàng lớn, việc sử dụng index giúp giảm thời gian truy vấn, đặc biệt là khi chỉ một phần nhỏ của dữ liệu cần được truy cập.
-
Khi cần sắp xếp dữ liệu
- Nếu cần sắp xếp dữ liệu theo một trình tự nhất định (ví dụ: sắp xếp theo thứ tự bảng chữ cái), việc tạo index sẽ giúp cải thiện hiệu suất của các truy vấn yêu cầu sắp xếp.
-
Khi cần hỗ trợ cho các ràng buộc duy nhất
- Index có thể được sử dụng để hỗ trợ các ràng buộc duy nhất (unique constraints) trên các cột, đảm bảo tính nhất quán của dữ liệu.
- Khi Trường Được Sử Dụng Trong Câu Lệnh WHERE và JOIN:
- Đánh index trên các cột được sử dụng thường xuyên trong điều kiện truy vấn WHERE hoặc trong các câu lệnh JOIN giúp cải thiện hiệu suất của các truy vấn này.
- Khi Cần Unique Constraint:
- Đánh index trên một hoặc nhiều cột có thể giúp đảm bảo rằng giá trị trong cột đó là duy nhất, bằng cách sử dụng ràng buộc duy nhất (unique constraint).
Không Nên Đánh Index Khi Nào
- Khi Cột Không Được Sử Dụng Trong Truy Vấn
- Nếu một cột không được sử dụng trong các truy vấn thường xuyên, việc đánh index trên cột đó có thể làm tăng tài nguyên cần thiết mà không đem lại lợi ích nào cho hiệu suất.
- Khi Cột Chứa Dữ Liệu Rất Lớn hoặc Lặp Lại Nhiều
- Đánh index trên các cột có dữ liệu lớn hoặc lặp lại nhiều có thể làm tăng kích thước của index mà không cải thiện hiệu suất.
- Khi Cần Thực Hiện Nhiều Thao Tác Ghi
- Đánh index trên các cột có thể làm chậm quá trình ghi dữ liệu mới vào bảng, đặc biệt khi cần thực hiện nhiều thao tác ghi (insert, update, delete) trên bảng đó.
Việc đánh index nên được thực hiện một cách cân nhắc, dựa trên cách cơ sở dữ liệu được sử dụng và loại truy vấn mà bạn đang thực hiện. Đánh index có thể cải thiện hiệu suất truy vấn trong nhiều trường hợp, nhưng cũng có thể gây ra tăng tải cho hệ thống nếu được sử dụng không đúng cách.
Chiến lược sử dụng index hiệu quả
-
Xác định những truy vấn cần tối ưu
- Trước tiên, xác định những truy vấn nào cần được tối ưu hóa bằng việc sử dụng index. Phân tích các truy vấn và xác định các cột cần được tạo index.
-
Tránh tạo quá nhiều index
- Mỗi index cần tài nguyên để lưu trữ và duy trì. Việc tạo quá nhiều index có thể dẫn đến sự lãng phí tài nguyên và làm giảm hiệu suất của cơ sở dữ liệu.
-
Cập nhật thường xuyên
- Cập nhật index đều đặn để đảm bảo tính nhất quán của dữ liệu và hiệu suất truy vấn.
-
Kiểm tra hiệu suất
- Liên tục kiểm tra hiệu suất của các truy vấn và điều chỉnh index khi cần thiết để đảm bảo hiệu suất tối ưu.
- Chú ý trình tự của index sẽ phụ thuộc vào thứ tự column
- Trong quá trình chúng ta tạo bảng, khi một giá trị trùng nhau thì giá trị tiếp theo sẽ được lấy làm tiêu chí để sắp xếp, ví dụ 2 người có cùng tên là Basinger Viven nhưng họ khác ngày sinh nên ngày sinh sẽ được dùng để sắp xếp.
-
Tầm Quan Trọng của Cột:
-
Nếu một cột được sử dụng thường xuyên trong các truy vấn SELECT, WHERE, hoặc JOIN, đánh index là hợp lý. Điều này đặc biệt quan trọng đối với các cột có sự đa dạng lớn trong giá trị.
-
-
Tải Lưu Lượng Truy Vấn:
-
Nếu cơ sở dữ liệu của bạn phải xử lý một lượng lớn truy vấn đồng thời hoặc một lượng lớn truy vấn có thời gian đáp ứng yêu cầu nhanh chóng, việc đánh index có thể hữu ích.
-
-
Kích Thước của Bảng:
-
Trong các bảng lớn có hàng triệu bản ghi, việc đánh index có thể giúp cải thiện hiệu suất truy vấn bằng cách giảm thời gian tìm kiếm.
-
-
Loại Dữ Liệu:
-
Cột chứa dữ liệu độc nhất, chẳng hạn như các trường ID hoặc trường mà giá trị của nó không thay đổi thường xuyên, thường là ứng viên tốt cho việc đánh index.
-
-
Khả Năng Tăng Tốc:
-
Nếu việc tăng tốc độ truy vấn được ưu tiên cao và tài nguyên hệ thống đủ, đánh index có thể thực hiện ngay cả trên các bảng có số lượng bản ghi không quá lớn.
-
Tuy nhiên, không nên đánh index quá nhiều, đặc biệt là trên các bảng có ít bản ghi hoặc các cột mà không được sử dụng thường xuyên trong truy vấn. Việc này có thể làm tăng overhead và làm chậm quá trình cập nhật dữ liệu. Thông thường, việc đánh index trên các bảng có hàng chục nghìn đến hàng triệu bản ghi là phổ biến, nhưng điều này có thể thay đổi tùy thuộc vào tình huống cụ thể của bạn.
Tại sao khi đánh index lại tốn nhiều RAM
Khi đánh index trong cơ sở dữ liệu và truy xuất dữ liệu từ index, việc tiêu tốn nhiều RAM có thể được giải thích bởi một số lý do sau:
- Lưu Trữ Index Trong Bộ Nhớ
- Index được lưu trữ trong bộ nhớ để tăng tốc độ truy xuất dữ liệu. Khi bạn đánh index trên một hoặc nhiều cột trong bảng, dữ liệu của các cột này cũng sẽ được lưu trữ trong bộ nhớ RAM, làm tăng dung lượng RAM tiêu tốn.
- Cấu Trúc Dữ Liệu Của Index
- Cấu trúc dữ liệu của index thường phức tạp và đòi hỏi một lượng lớn bộ nhớ để lưu trữ. Ví dụ, cây B-tree, một trong những cấu trúc dữ liệu phổ biến được sử dụng cho index, đòi hỏi một lượng lớn bộ nhớ để lưu trữ nút và các con trỏ.
- Số Lượng Phần Tử trong Index
- Nếu index được tạo trên một cột có số lượng phần tử lớn, index cũng sẽ lớn theo và đòi hỏi nhiều bộ nhớ hơn để lưu trữ. Điều này có thể làm tăng lượng RAM tiêu tốn khi truy xuất dữ liệu từ index.
- Cache
- Cơ sở dữ liệu có thể sử dụng cache để lưu trữ một phần của index hoặc dữ liệu được truy xuất gần đây trong bộ nhớ RAM để giảm thời gian truy xuất dữ liệu từ ổ đĩa. Việc sử dụng cache có thể làm tăng lượng RAM tiêu tốn.
- Số Lượng Truy Vấn Đồng Thời
- Nếu có nhiều truy vấn đồng thời được thực hiện trên cơ sở dữ liệu và mỗi truy vấn đều sử dụng index, lượng RAM tiêu tốn sẽ tăng lên do cần lưu trữ index cho mỗi truy vấn.
Nó lưu những gì vào trong RAM
Việc lưu trữ index trong bộ nhớ không đồng nghĩa với việc lưu trữ tất cả các bản ghi của một bảng (table) vào RAM. Khi một cột được đánh index, chỉ những giá trị của cột đó cùng với các con trỏ tới vị trí tương ứng của các bản ghi trong bảng được lưu trữ trong index. Dữ liệu thực sự của các bản ghi không cần phải được lưu trữ trong bộ nhớ RAM khi chỉ index được lưu trữ.
Cụ thể, khi một cột được đánh index, cơ sở dữ liệu sẽ tạo ra một cấu trúc dữ liệu tối ưu (như cây B-tree) để lưu trữ các giá trị của cột đó cùng với các con trỏ tới vị trí của các bản ghi tương ứng trong bảng. Khi cần truy xuất dữ liệu dựa trên cột được đánh index, cơ sở dữ liệu sẽ sử dụng index để nhanh chóng định vị các bản ghi và trả về kết quả cho truy vấn.
Tóm lại, index trong bộ nhớ RAM chỉ lưu trữ thông tin về giá trị của cột và các con trỏ tới vị trí của các bản ghi trong bảng, không phải toàn bộ dữ liệu của bảng. Điều này giúp tối ưu hóa hiệu suất truy vấn mà không cần phải lưu trữ toàn bộ dữ liệu của bảng trong bộ nhớ.
Đánh index nhưng kết quả trả về quá lớn thì sẽ làm như thế nào?
Khi dữ liệu trả về từ các truy vấn sử dụng index quá lớn và gây ra overhead hoặc vấn đề về bộ nhớ, có một số cách giải quyết và tối ưu để xử lý tình huống này:
- Tối Ưu Truy Vấn:
-
Chỉ Chọn Các Cột Cần Thiết: Thay vì chọn tất cả các cột trong truy vấn, chỉ chọn các cột cần thiết để giảm lượng dữ liệu trả về.
-
Sử Dụng LIMIT: Sử dụng LIMIT trong truy vấn để giới hạn số lượng bản ghi trả về.
-
Tối Ưu Câu Lệnh WHERE: Tối ưu câu lệnh WHERE để giảm số lượng bản ghi được truy vấn.
-
- Tối Ưu Index:
-
Chọn Lựa Cột Phù Hợp: Chọn lựa các cột thích hợp để đánh index, tránh đánh index trên các cột không cần thiết hoặc có dữ liệu lặp lại nhiều.
-
Xóa Index Không Cần Thiết: Kiểm tra và xóa các index không cần thiết để giảm overhead.
-
- Tăng Cấu Hình Bộ Nhớ:
- Tăng Cấu Hình Bộ Nhớ: Tăng cấu hình bộ nhớ cho cơ sở dữ liệu để có thêm tài nguyên để xử lý lượng dữ liệu lớn.
- Sử Dụng Phân Trang (Pagination):
- Phân Trang: Sử dụng phân trang để chia nhỏ lượng dữ liệu trả về thành các trang nhỏ hơn và trả về từng trang một.
- Cân Nhắc Sử Dụng Cache:
- Sử Dụng Cache: Sử dụng cache để lưu trữ một phần của dữ liệu truy vấn gần đây trong bộ nhớ, giảm overhead khi truy xuất dữ liệu từ cơ sở dữ liệu.
- Đánh Giá Và Tối Ưu Cấu Trúc Dữ Liệu:
- Đánh Giá Cấu Trúc Dữ Liệu: Xem xét lại cấu trúc dữ liệu để xem xét việc tối ưu hóa và loại bỏ các dữ liệu không cần thiết.
- Cân Nhắc Tối Ưu Hóa Cơ Sở Dữ Liệu:
- Tối Ưu Hóa Cơ Sở Dữ Liệu: Nếu tất cả các biện pháp trên không giải quyết được vấn đề, cân nhắc tối ưu hóa cơ sở dữ liệu để xử lý hiệu quả hơn với lượng dữ liệu lớn.
Kết quả của mỗi biện pháp sẽ phụ thuộc vào cấu trúc và yêu cầu cụ thể của ứng dụng và cơ sở dữ liệu. Việc thử nghiệm và đánh giá kết quả sau mỗi biện pháp cũng là điều quan trọng để chọn lựa biện pháp tối ưu nhất cho tình huống cụ thể của bạn.
Cập nhật index như thế nào
Cập nhật index trong cơ sở dữ liệu là quá trình thực hiện khi dữ liệu trong bảng được thay đổi, và bạn cần cập nhật index để đảm bảo rằng chúng vẫn phản ánh đúng cấu trúc dữ liệu mới. Dưới đây là các bước cơ bản để cập nhật index:
- Thực Hiện Cập Nhật Dữ Liệu Trong Bảng:
- Trước tiên, bạn cần thực hiện các thao tác cập nhật dữ liệu trong bảng, bao gồm thêm mới, sửa đổi hoặc xóa bản ghi.
- Cập Nhật Index:
- Sau khi dữ liệu đã được cập nhật, bạn cần cập nhật lại index để đảm bảo rằng chúng vẫn phản ánh chính xác dữ liệu mới. Cách cập nhật index có thể thực hiện theo các phương pháp sau:
-
- Tự Động Cập Nhật:
- Một số cơ sở dữ liệu hỗ trợ tự động cập nhật index khi có thay đổi dữ liệu trong bảng. Trong trường hợp này, bạn không cần phải làm gì thêm, hệ thống sẽ tự động cập nhật index cho bạn.
- Sử Dụng Câu Lệnh SQL:
- Bạn có thể sử dụng các câu lệnh SQL để cập nhật index. Ví dụ, trong MySQL, bạn có thể sử dụng câu lệnh ALTER TABLE để tái tạo hoặc tái xây dựng index:
-
ALTER TABLE table_name DROP INDEX index_name, ADD INDEX index_name(column_name);
- Sử Dụng Công Cụ Quản Lý Cơ Sở Dữ Liệu:
- Các công cụ quản lý cơ sở dữ liệu cung cấp các chức năng để cập nhật index. Thông qua giao diện của công cụ này, bạn có thể chọn bảng và index cần cập nhật, sau đó thực hiện các hành động cập nhật index.
- Tự Động Cập Nhật:
- Kiểm Tra và Kiểm Soát Quá Trình Cập Nhật
- Sau khi cập nhật index, hãy kiểm tra kết quả để đảm bảo rằng các index được cập nhật đúng cách và phản ánh chính xác dữ liệu mới.
Lưu Ý:
-
Thời Gian Cập Nhật: Quá trình cập nhật index có thể tốn kém và ảnh hưởng đến hiệu suất hệ thống, đặc biệt khi bạn có một lượng lớn dữ liệu.
-
Tối Ưu Hóa Cập Nhật: Khi cập nhật index, cố gắng tối ưu hóa quá trình này bằng cách chọn thời điểm thích hợp và sử dụng các công cụ và kỹ thuật tối ưu.
-
Đánh Giá Tài Nguyên: Trước khi thực hiện cập nhật index, đảm bảo rằng bạn có đủ tài nguyên và không gây ra tình trạng quá tải cho hệ thống.
Có thể bạn chưa biết
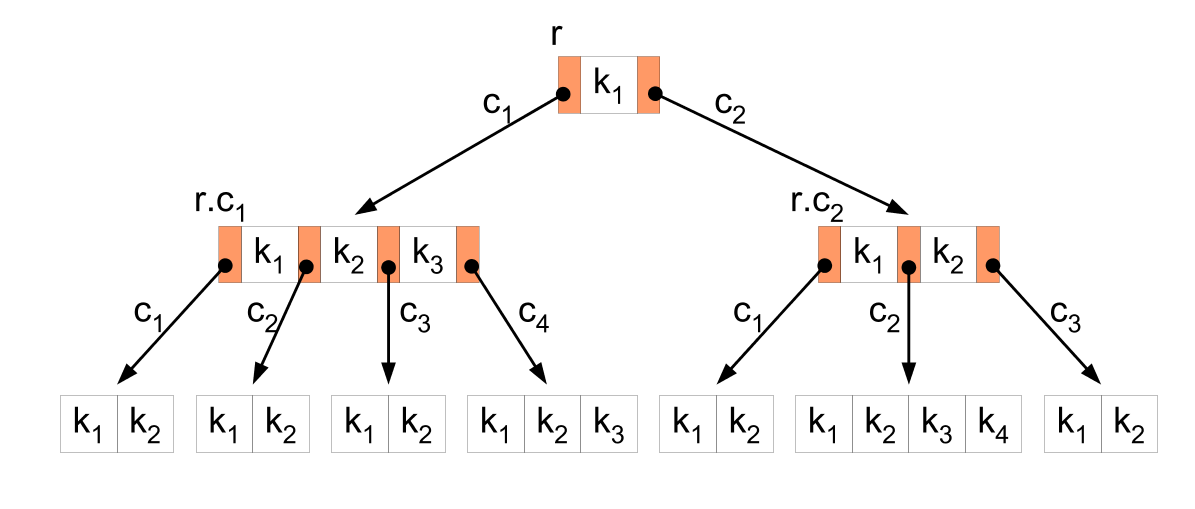
B-Tree index tăng tốc độ truy vấn dữ liệu vì storage engine không phải duyệt cả bảng để tìm kiếm dữ liệu mà nó sẽ đi từ node root. các vị trí root node sẽ chưa con trỏ tới những node con, nó tìm đúng con trỏ bằng cách nhìn vào các giá trị trong node con và bằng việc xác định các giới hạn trên và dưới của một node, giúp storage engine dễ dàng tìm kiếm sự tồn tại hay không của một giá trị.
1. Cấu Trúc Cây B-tree
Cây B-tree là một cấu trúc dữ liệu cây có thứ tự, phân cấp, và được sử dụng rộng rãi trong cơ sở dữ liệu. Mỗi nút trong cây B-tree chứa một tập hợp các khóa và con trỏ. Cây B-tree thỏa mãn các điều kiện sau:
- Mỗi nút chứa tối đa khóa và
con trỏ. - Mỗi nút, trừ nút gốc, có ít nhất [m/2]khóa.
- Tất cả các lá cùng nằm ở cùng một mức.
2. Quá Trình Lập Chỉ Mục Cây B-tree
Khi lập chỉ mục cây B-tree trong cơ sở dữ liệu, quá trình sẽ diễn ra như sau:
Bước 1: Sắp Xếp Dữ Liệu
Dữ liệu trong bảng được sắp xếp theo thứ tự của khóa mà bạn muốn tạo index. Điều này giúp tạo ra một cây B-tree có cấu trúc tốt hơn và tối ưu hóa thời gian truy cập.
Bước 2: Tạo Nút Gốc
Nút gốc của cây B-tree được tạo ra, và dữ liệu đầu tiên của bảng được chèn vào nút này.
Bước 3: Chia Nút
Nếu nút đã đầy (tức là số lượng khóa vượt quá ), nút sẽ được chia thành hai nút con. Phần giữa của nút sẽ được chuyển lên nút cha, và các phần còn lại sẽ được chia đều vào hai nút con.
Bước 4: Chèn Dữ Liệu
Dữ liệu tiếp theo của bảng sẽ được chèn vào cây B-tree theo thứ tự của khóa. Quá trình này lặp lại cho tới khi tất cả các dữ liệu được chèn vào cây.
Bước 5: Cập Nhật Cây
Sau mỗi lần chèn dữ liệu, cây B-tree sẽ được cập nhật để đảm bảo rằng nó vẫn tuân thủ các điều kiện của một cây B-tree.
3. Quá Trình Truy Xuất Dữ Liệu Từ Chỉ Mục
Khi cần truy xuất dữ liệu từ chỉ mục cây B-tree, quá trình thực hiện như sau:
Bắt đầu từ nút gốc của cây.
So sánh khóa cần tìm với các khóa trong nút hiện tại.
Nếu khóa cần tìm nằm trong khoảng của nút, tiếp tục tìm kiếm trong nút con tương ứng.
Lặp lại quá trình cho đến khi tìm thấy khóa hoặc đạt đến nút lá.
Kết luận
Index đóng vai trò quan trọng trong việc tối ưu hóa hiệu suất truy vấn trong cơ sở dữ liệu. Việc sử dụng index một cách hiệu quả đòi hỏi sự hiểu biết về cấu trúc dữ liệu và các truy vấn được thực hiện trên cơ sở dữ liệu. Bằng cách chọn lựa và tối ưu hóa index một cách cẩn thận, bạn có thể cải thiện đáng kể hiệu suất và hiệu quả của ứng dụng của mình.

















Bình luận (0)