
- AWS Introduction
- AWS Overview
- Tạo Tài Khoản AWS Miễn Phí
- The First Setting - AWS
- Tạo AWS Budget
- IAM Service
- Identity And Access Management (IAM) - Overview
- Thực Hành: Buộc Người Dùng IAM Bật MFA Trước Khi Sử Dụng Dịch Vụ AWS
- EC2 Service - Foundation
- AWS EC2 Service - Overview
- AWS EC2 Service - Network & Security
- EC2 Service - EC2 Fleet
- Elastic Block Store (EBS)
- Elastic File System (EFS)
- Thực Hành: EFS - Cách Triển Khai EFS Và Access Points Với Nhiều EC2
- So Sánh EBS Và EFS
- EC2 Service - Elastic Load Balancing & Auto Scaling Group
- Giới Thiệu Elastic Load Balancing
- Classic Load Balancers
- Application Load Balancer
- Network Load Balancer & Gateway Load Balancer
- So Sánh Giữa Classic, Application, Network, và Gateway Load Balancers
- Auto Scaling Group in AWS
- Thực Hành: Triển khai Ứng Dụng Laravel Với Auto Scaling Và Load Balancing Trên AWS
- S3 Service
- AWS S3 Service
- S3 Service - Features
- Thực Hành: Triển Khai Upload File Lên S3 Bằng Laravel Và Multipart Upload
- Thực Hành: Upload Files Vào S3 Từ EC2 Instance Với IAM Role Cho Laravel App Production
- RDS, Aurora & ElastiCache
- AWS Relational Database Service
- Thực Hành - Kết Nối RDS Private Tới EC2 Instance Và Lambda Function (Nodejs)
- Thực Hành: RDS Service - Blue/Green Deployments
- AWS Aurora Service
- Thực Hành: Triển Khai Master - Slave Trong Laravel Sử Dụng Read Replica Amazon RDS
- VPC
- Virtual Private Cloud (VPC)
- Virtual Private Cloud (VPC) - Phần 2
Amazon Aurora
-
Aurora là công nghệ độc quyền từ AWS (not open sourced): Aurora là một dịch vụ cơ sở dữ liệu quan trọng từ AWS, được phát triển và duy trì bởi Amazon.
-
Hỗ trợ cả Postgres và MySQL như là Aurora DB (điều đó có nghĩa là các trình điều khiển của bạn sẽ hoạt động như là Aurora là một cơ sở dữ liệu Postgres hoặc MySQL) Aurora có khả năng hoạt động với cả hai phiên bản cơ sở dữ liệu, giúp tối ưu hóa sự linh hoạt và tương thích.
-
Aurora được tối ưu cho "AWS cloud optimized": Aurora cải thiện hiệu suất lên đến 5 lần so với MySQL trên RDS, hơn 3 lần so với Postgres trên RDS, Aurora được thiết kế để hoạt động hiệu quả trên nền tảng đám mây của AWS và hứa hẹn cải thiện hiệu suất đáng kể so với các phiên bản cơ sở dữ liệu truyền thống.
-
Lưu trữ Aurora tự động tăng lên theo các khoảng 10GB, lên đến 128 TB: Aurora cung cấp khả năng mở rộng linh hoạt cho nhu cầu lưu trữ ngày càng tăng.
-
Aurora có thể có tối đa 15 replicas và quá trình sao chép nhanh hơn MySQL (replica lag dưới 10 ms): Aurora cung cấp khả năng sao chép linh hoạt và hiệu quả.
-
Việc chuyển đổi sang bản sao chính của Aurora là tức thì. Nó là một hệ thống cao sẵn có (HA - High Availability) mặc định: Aurora đảm bảo khả năng hoạt động liên tục và kiên định, giúp hạn chế sự gián đoạn trong dịch vụ.
-
Aurora có giá cao hơn RDS (tăng 20%) - nhưng hiệu quả hơn: Dịch vụ Aurora có giá cao hơn so với RDS, nhưng hiệu quả hơn đáng kể và đáp ứng được nhu cầu sử dụng cao cấp hơn của các doanh nghiệp.
- Usecases: Recommend to use instead of MySQL & PostgreSQL
- Price: https://aws.amazon.com/rds/pricing
Comparing
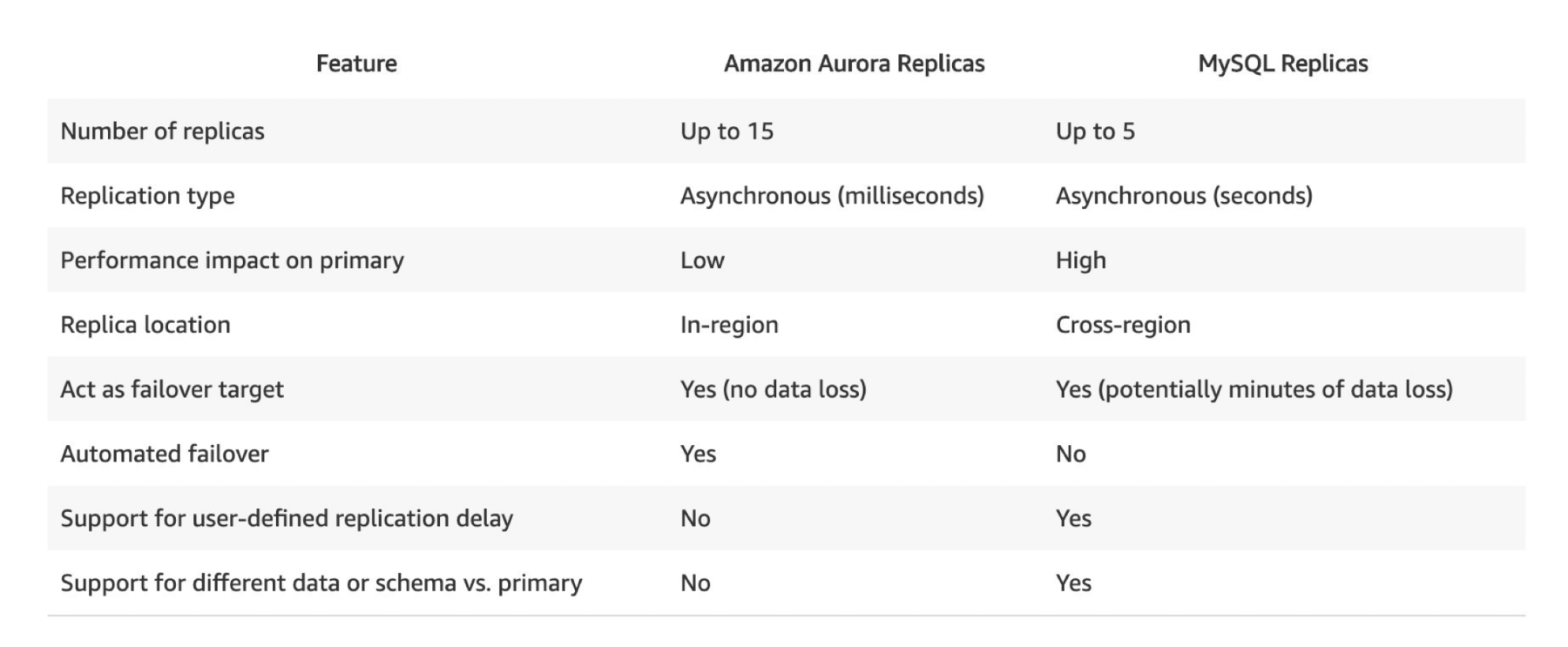
Aurora costs more than RDS (20% more) - but is more efficient
Demo
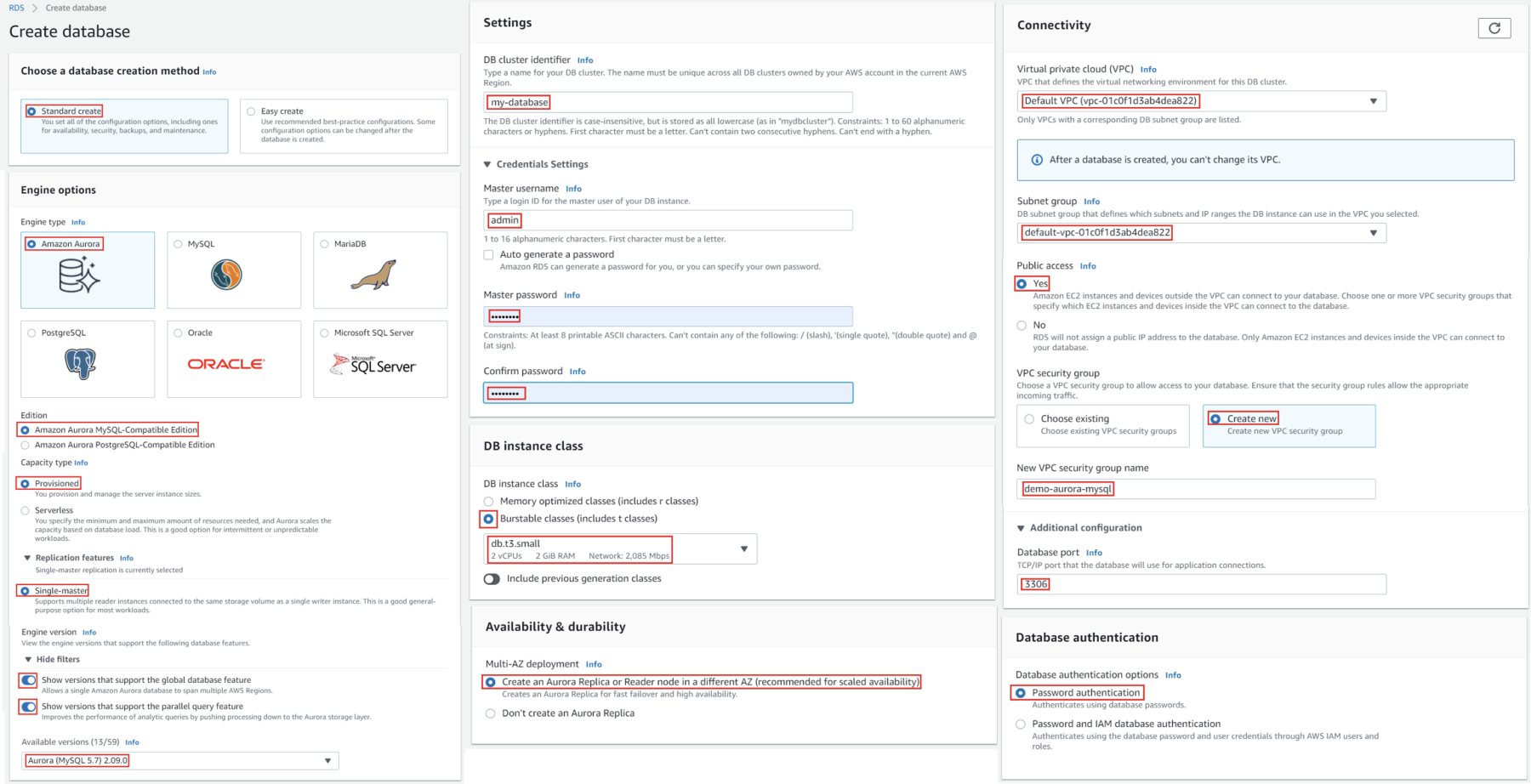
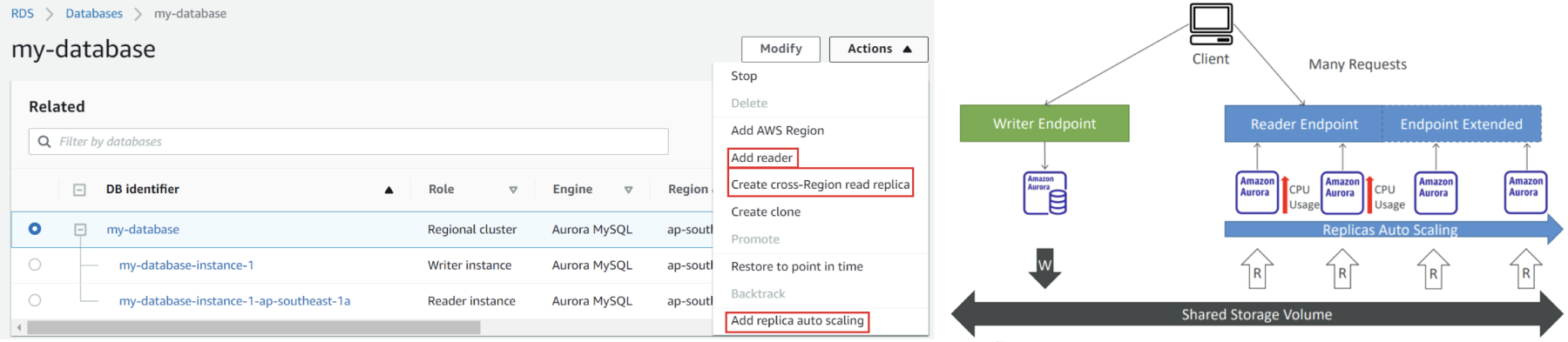
1. Create Database
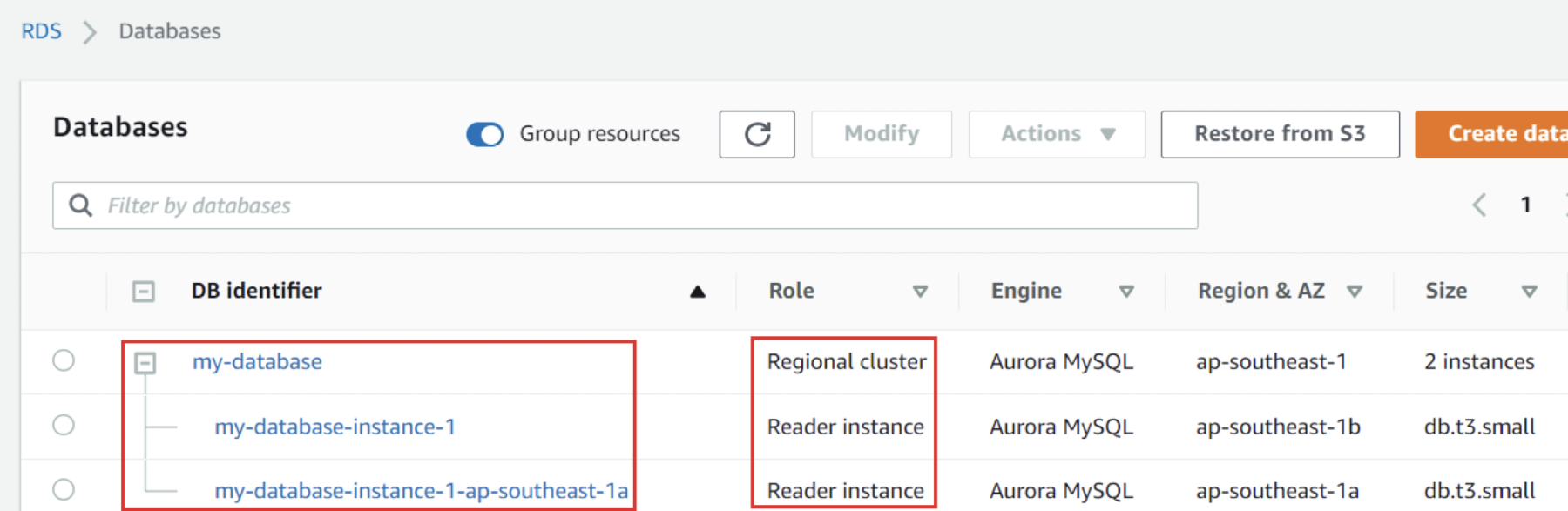
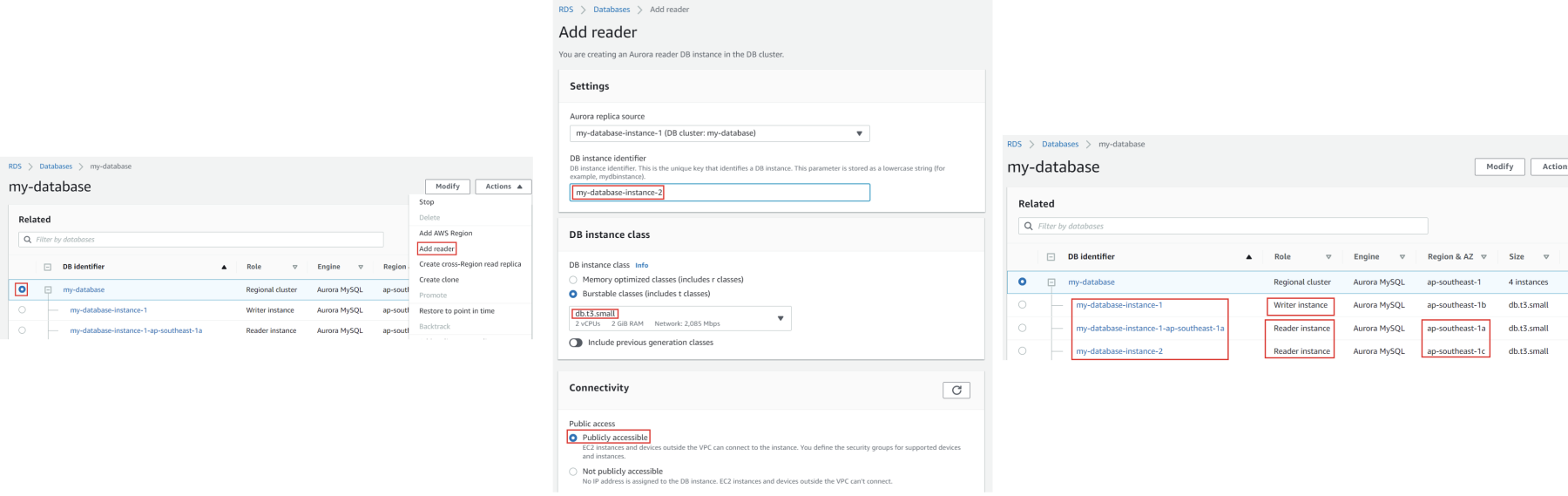
2. Add more reader instance
Components
|
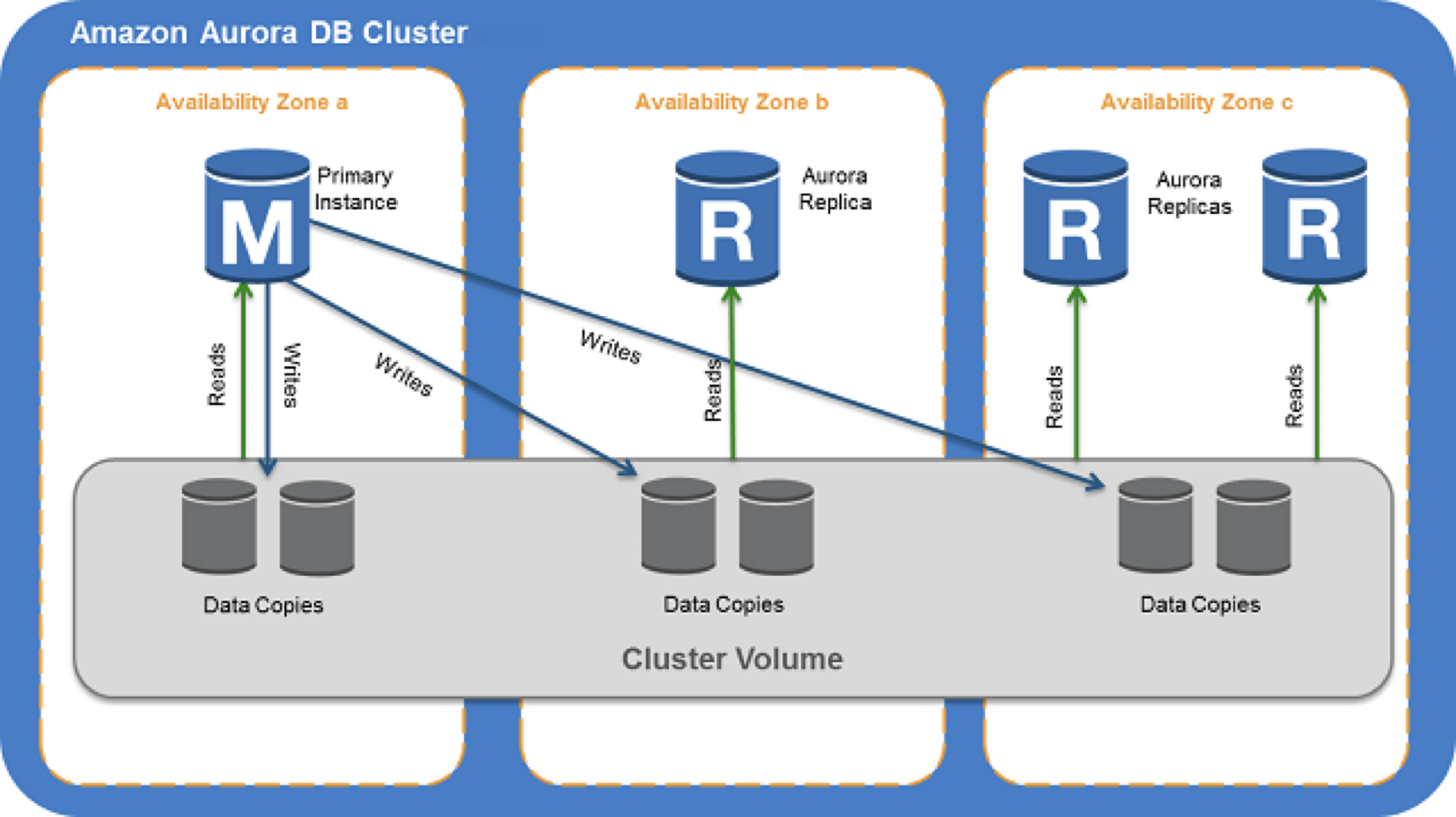 |
DB Cluster
DB Cluster trong RDS Aurora là một tập hợp các DB Instances liên kết với nhau để tạo ra một hệ thống cơ sở dữ liệu phân tán và có khả năng chịu lỗi. Cụ thể:
- DB Cluster hoạt động trong một vùng (region) của AWS.
- Bao gồm ít nhất một DB Instance chức năng viết (writer) và nhiều DB Instances chức năng đọc (reader).
- Cung cấp một endpoint cho request ghi dữ liệu và một endpoint cho request đọc dữ liệu.
DB Cluster trong RDS Aurora giúp tối ưu hóa hiệu suất và độ tin cậy của hệ thống cơ sở dữ liệu bằng cách phân phối tải và cung cấp khả năng mở rộng ngang (horizontal scaling).
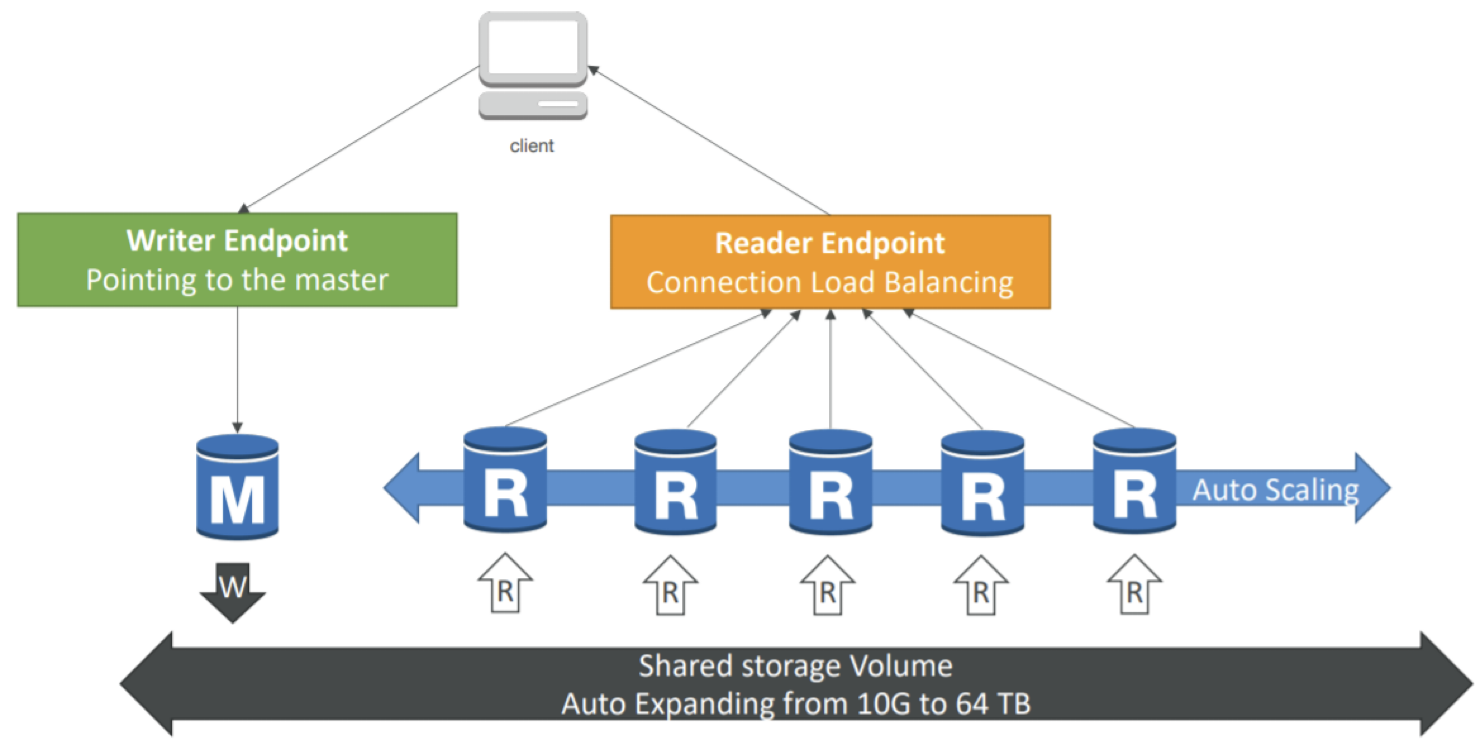 |
Endpoint |
DB Instance
-
Working in a zone: DB Instance hoạt động trong một khu vực cụ thể của AWS. Khu vực (zone) là một phần của một vùng (region) trong hệ thống AWS. Một DB Instance được triển khai trong một khu vực nhất định.
-
Support 2 database engine: MySQL & PostgreSQL: Aurora hỗ trợ hai loại cơ sở dữ liệu: MySQL và PostgreSQL. Điều này cho phép người dùng lựa chọn động giữa hai loại cơ sở dữ liệu phổ biến này tùy thuộc vào yêu cầu cụ thể của ứng dụng.
-
Setup: Hardware, Networking, Security, Master account, Database authentication, Database, Backup, monitoring, log, Maintenance, Delete protection, ... Similar to RDS: Aurora cung cấp các tính năng giống như Amazon RDS trong việc thiết lập và quản lý một DB Instance. Điều này bao gồm các khía cạnh như Hardware, Networking, Security, Master account, Database authentication, Database , Backup, monitoring, log, Maintenance, Delete protection...
- 2 types: Primary DB Instance, Aurora Replica:
- Primary DB Instance:
- Loại DB Instance chính được sử dụng cho các yêu cầu read/write.
- Có thể sửa đổi dữ liệu trong cluster volume.
- Aurora Replica:
- Loại DB Instance sao chép được sử dụng cho các request read.
- Hỗ trợ Cross A-Z, Cross region, Auto Scaling (tự động co giãn), và Automatic failover (tự động chuyển đổi).
- Automatic failover: Tự động gán replica cho Primary DB Instance khi Primary DB Instance không khả dụng trong vòng ít hơn 30 giây.
- Số lượng replica tối đa là 15, thường được cấu hình mỗi khu vực sẽ có 1 DB Instance để tăng tính sẵn sàng cao.
- Primary DB Instance:
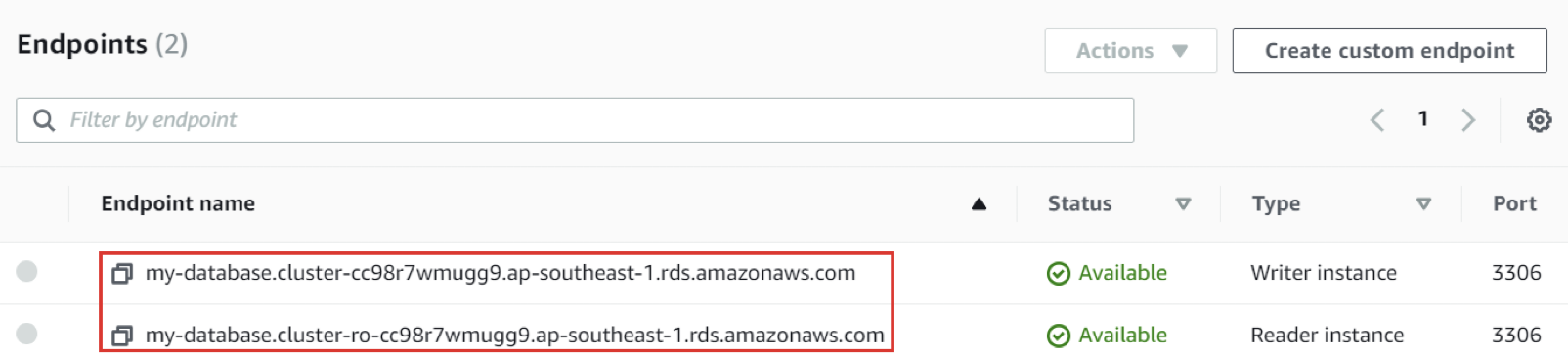
Custom Endpoints
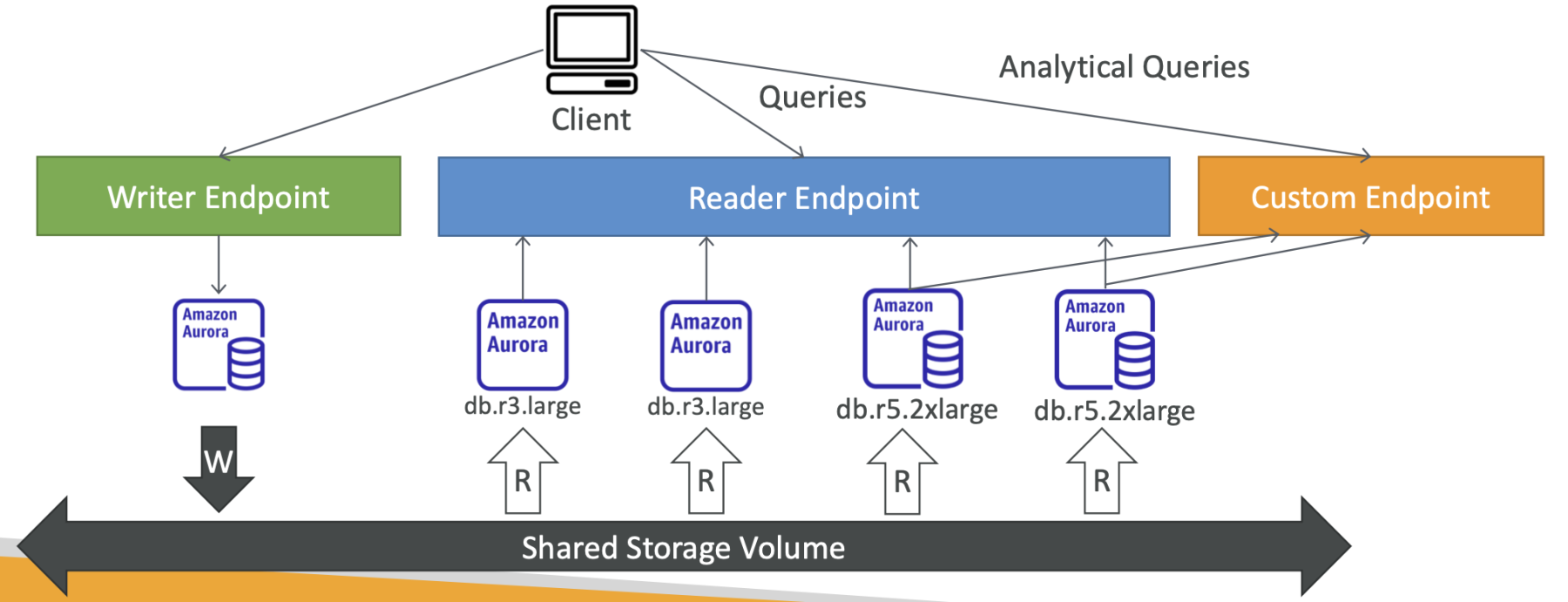
-
Định nghĩa một tập hợp các Aurora Instances là một Custom Endpoint: Tính năng này cho phép bạn xác định một nhóm các Aurora Instances nhất định và gán chúng vào một Custom Endpoint. Điều này giúp tạo ra một điểm kết nối tùy chỉnh cho các tác vụ hoặc ứng dụng cụ thể.
-
Ví dụ: Chạy các truy vấn phân tích trên các replica cụ thể: Bằng cách sử dụng Custom Endpoints, bạn có thể xác định các replica cụ thể trong cụm Aurora và sử dụng chúng để chạy các truy vấn phân tích hoặc truy vấn đọc-intensive mà không ảnh hưởng đến các replica khác hoặc primary instance.
-
Endpoint đọc thường không được sử dụng sau khi xác định Custom Endpoints: Một khi bạn đã xác định Custom Endpoints, thường thì Endpoint đọc mặc định không còn được sử dụng nữa. Thay vào đó, các truy vấn đọc hoặc phân tích được chuyển hướng đến Custom Endpoints đã được xác định.
Aurora Serverless
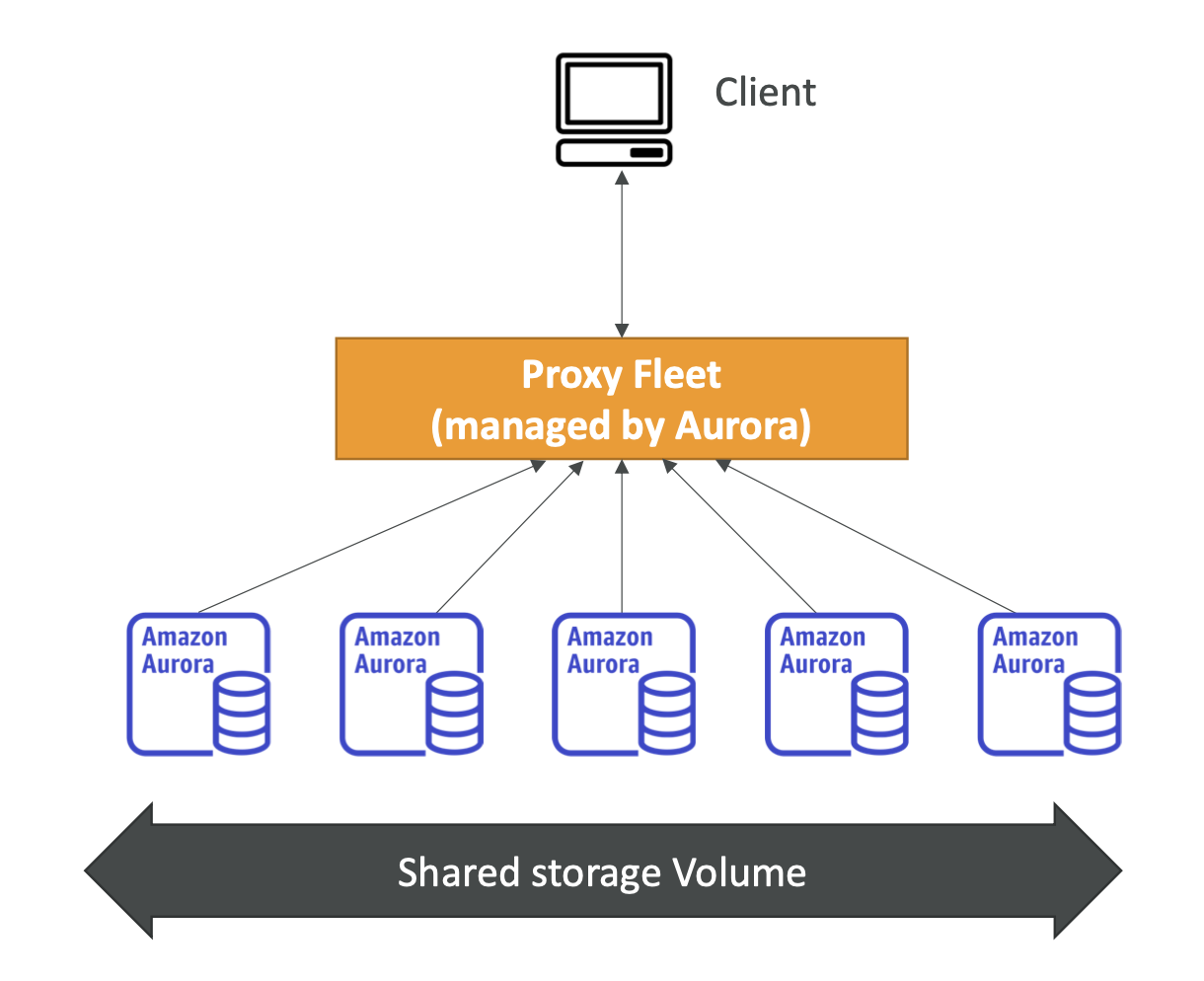
-
Tự động khởi tạo cơ sở dữ liệu và tự động mở rộng dựa trên việc sử dụng thực tế: Aurora Serverless tự động tạo và mở rộng các cụm cơ sở dữ liệu dựa trên tải công việc thực tế. Điều này giúp đảm bảo rằng tài nguyên chỉ được sử dụng khi cần thiết, giúp tối ưu hiệu suất và tối ưu hóa chi phí.
-
Phù hợp với các công việc ít xảy ra, không đều hoặc không dự đoán được: Aurora Serverless là lựa chọn lý tưởng cho các ứng dụng có công việc truy vấn hoặc ghi dữ liệu không đều hoặc không dự đoán được, vì nó tự động điều chỉnh tài nguyên để phản ánh tải làm việc thực tế.
-
Không cần kế hoạch dung lượng: Với Aurora Serverless, không cần phải lập kế hoạch cho dung lượng cơ sở dữ liệu trước. Hệ thống tự động quản lý và điều chỉnh tài nguyên để đáp ứng nhu cầu thực tế của ứng dụng.
-
Thanh toán theo giây, có thể tiết kiệm chi phí: Aurora Serverless áp dụng mô hình thanh toán theo giây, cho phép bạn chỉ trả tiền cho tài nguyên bạn sử dụng thực sự. Điều này có thể tạo ra chi phí hiệu quả hơn so với việc trả trước theo giờ hoặc theo dung lượng.
Aurora Multi-Master
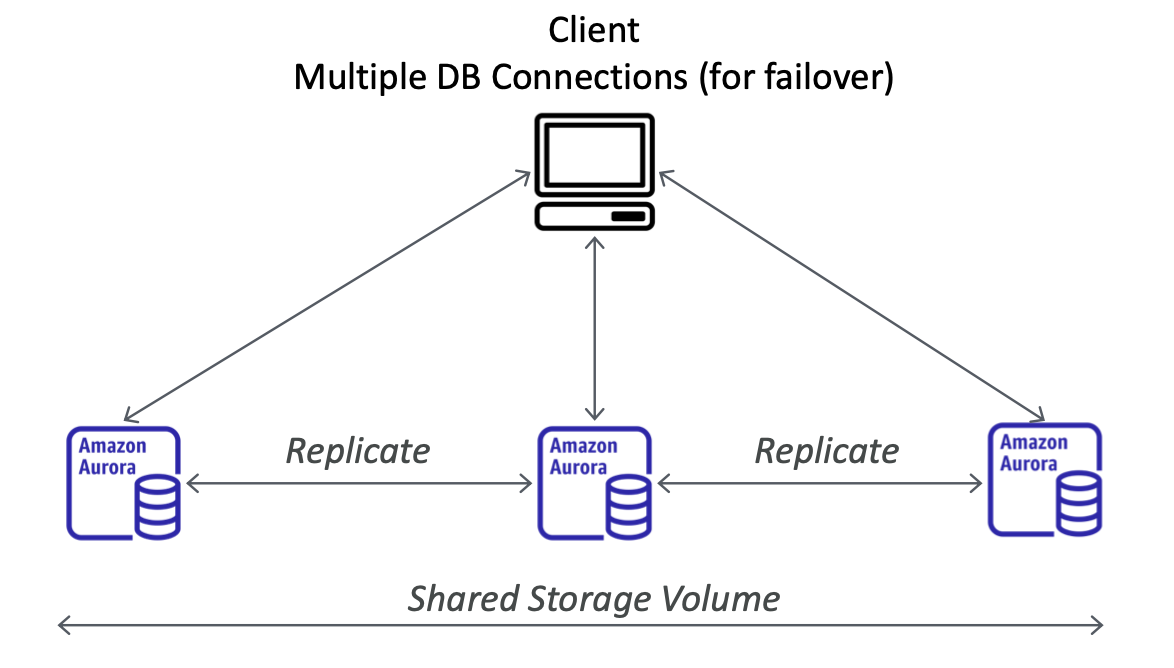 Đây là một tính năng của Amazon, Aurora cho phép mỗi node (hoặc instance) trong cụm Aurora đóng vai trò là master, nghĩa là mỗi node đều có khả năng đọc và ghi dữ liệu. Điều này mang lại khả năng failover ngay lập tức cho nút ghi (write node), tăng tính sẵn sàng cao (HA) của hệ thống.
Đây là một tính năng của Amazon, Aurora cho phép mỗi node (hoặc instance) trong cụm Aurora đóng vai trò là master, nghĩa là mỗi node đều có khả năng đọc và ghi dữ liệu. Điều này mang lại khả năng failover ngay lập tức cho nút ghi (write node), tăng tính sẵn sàng cao (HA) của hệ thống.
Trong trường hợp có sự cố xảy ra với một nút ghi (ví dụ: hỏng hoặc không thể truy cập), các (write requests) có thể tự động được chuyển đến các nút ghi khác mà không cần phải chờ đợi quá trình thực hiện failover như trong các kiến trúc thông thường. Điều này giúp giảm thiểu thời gian downtime và đảm bảo tính liên tục của ứng dụng.
Aurora Global Database
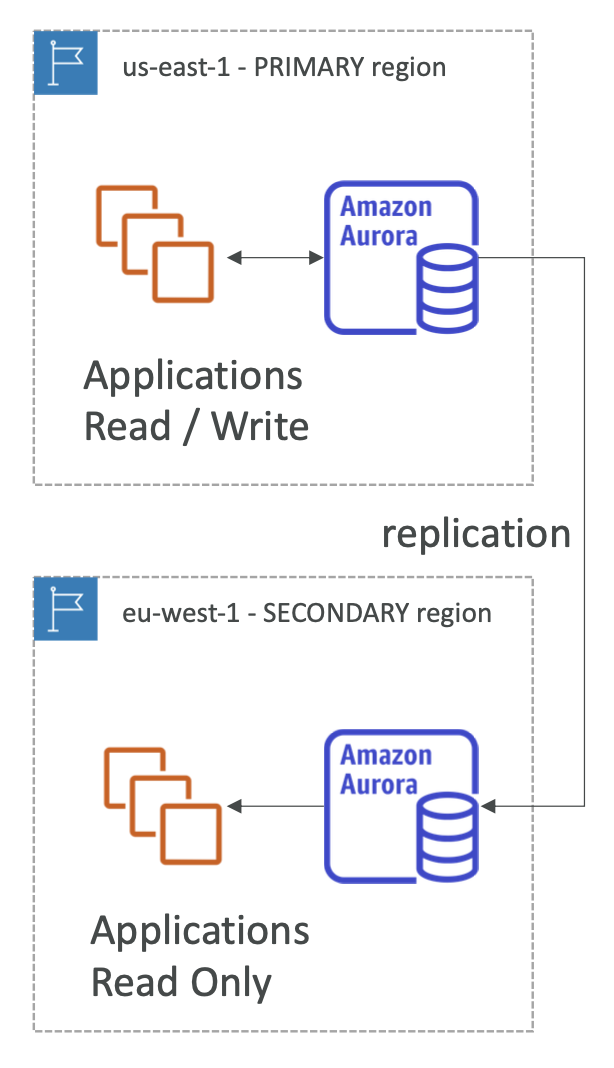
- Aurora Cross Region Read Replicas:
- Cung cấp khả năng tạo ra các bản sao đọc ở các khu vực khác nhau, hữu ích cho phòng chống thảm họa.
- Dễ dàng triển khai và cấu hình.
- Aurora Global Database (được khuyến nghị):
- Bao gồm một vùng chính (đọc/ghi) và đến 5 vùng phụ (chỉ đọc), với độ trễ sao chép ít hơn 1 giây.
- Mỗi vùng phụ có thể có đến 16 bản sao đọc.
- Giúp giảm độ trễ mạng bằng cách phân phối các bản sao đọc gần hơn với người dùng.
- Quá trình chuyển đổi vùng chính (để phòng chống thảm họa) có thời gian phục hồi dự tính dưới 1 phút.
- Thời gian sao chép giữa các khu vực vượt biên thông thường diễn ra trong vòng 1 giây.
Aurora Machine Learning
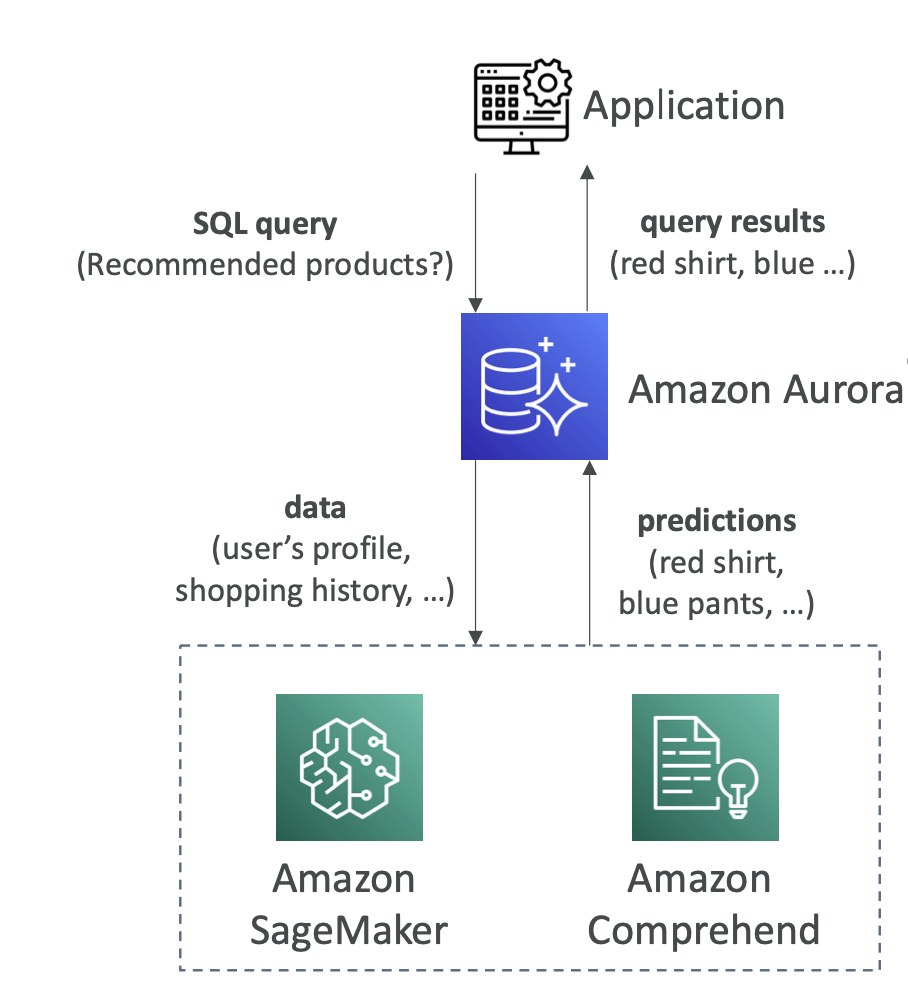
-
Thêm các dự đoán dựa trên học máy vào ứng dụng của bạn qua SQL: Aurora Machine Learning cho phép bạn tích hợp các dự đoán dựa trên học máy trực tiếp vào ứng dụng của mình thông qua câu lệnh SQL.
-
Tích hợp đơn giản, tối ưu hóa và an toàn giữa Aurora và các dịch vụ ML của AWS: Aurora Machine Learning cung cấp tích hợp đơn giản và an toàn giữa dịch vụ cơ sở dữ liệu Aurora và các dịch vụ Machine Learning của AWS.
-
Các dịch vụ được hỗ trợ:
- Amazon SageMaker: Cho phép sử dụng với bất kỳ mô hình học máy nào.
- Amazon Comprehend: Sử dụng để phân tích cảm xúc trong văn bản.
-
Không cần có kinh nghiệm về Machine Learning: Aurora Machine Learning giúp người dùng có thể sử dụng các dịch vụ Machine Learning mà không cần có kiến thức chuyên sâu về lĩnh vực này.
-
Các ứng dụng sử dụng: Bao gồm nhận diện gian lận, phát hiện lựa chọn quảng cáo, phân tích cảm xúc và đề xuất sản phẩm.
RDS Backups
-
Automated backups:
- Sao lưu tự động hàng ngày của cơ sở dữ liệu (trong khung giờ sao lưu)
- Nhật ký giao dịch được sao lưu bởi RDS mỗi 5 phút
- Khả năng khôi phục đến bất kỳ thời điểm nào (từ bản sao lưu cũ nhất đến 5 phút trước đây)
- Lưu trữ từ 1 đến 35 ngày, có thể đặt 0 để vô hiệu hóa sao lưu tự động
-
Manual DB Snapshots:
- Tạo bản sao lưu thủ công bởi người dùng
- Lưu trữ bản sao lưu trong thời gian mà bạn muốn
-
Lưu ý:
- Trong trường hợp một cơ sở dữ liệu RDS bị tắt, bạn vẫn phải trả phí cho việc lưu trữ. Nếu bạn dự định tắt nó trong một thời gian dài, bạn nên tạo bản sao lưu và khôi phục thay vì dừng cơ sở dữ liệu.
Aurora Backups
- Automated backups:
- Cung cấp sao lưu tự động hàng ngày trong khoảng thời gian từ 1 đến 35 ngày.
- Không thể tắt tính năng sao lưu tự động này.
- Cho phép khôi phục đến điểm trong thời gian đó.
- Manual DB Snapshots:
- Người dùng có thể kích hoạt sao lưu thủ công.
- Bạn có thể giữ lại sao lưu này trong thời gian mà bạn muốn, không giới hạn.
RDS & Aurora Restore options
-
Khôi phục sao lưu hoặc snapshot của RDS / Aurora: Tạo một cơ sở dữ liệu mới từ một bản sao lưu hoặc snapshot đã tồn tại. Điều này cho phép bạn khôi phục dữ liệu đã sao lưu hoặc trạng thái của cơ sở dữ liệu tại thời điểm snapshot được tạo.
-
Khôi phục cơ sở dữ liệu MySQL RDS từ S3:
- Tạo một bản sao lưu của cơ sở dữ liệu trên on-premises của bạn.
- Lưu trữ nó trên Amazon S3 (lưu trữ object).
- Khôi phục tệp sao lưu vào một RDS instance mới chạy MySQL.
-
Khôi phục cụm Aurora MySQL từ S3:
- Tạo một bản sao lưu của cơ sở dữ liệu trên nền tảng của bạn bằng Percona XtraBackup.
- Lưu trữ tệp sao lưu trên Amazon S3.
- Khôi phục tệp sao lưu vào một cụm Aurora mới chạy MySQL.
Aurora Database Cloning
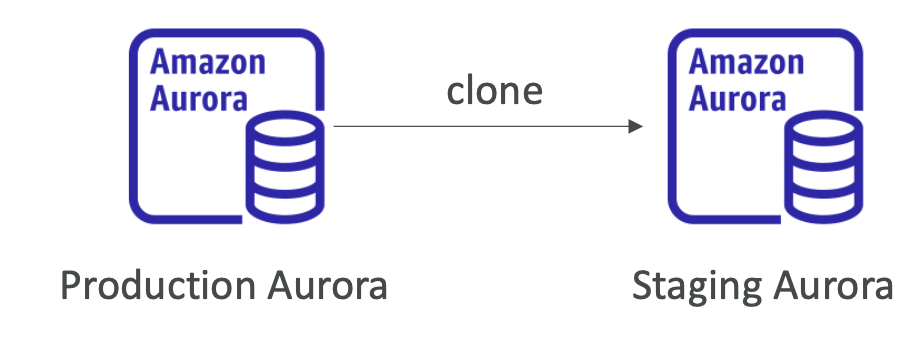
-
Tạo một Aurora DB Cluster mới từ một DB Cluster hiện có: Cho phép tạo ra một bản sao của DB Cluster Aurora từ một DB Cluster đã tồn tại, giúp tạo ra một môi trường staging hoặc phát triển mới mà không ảnh hưởng đến DB Cluster sản xuất.
-
Nhanh hơn so với snapshot & restore: Quá trình tạo ra DB Cluster mới từ cloning nhanh hơn so với việc sử dụng snapshot và phục hồi, giúp tiết kiệm thời gian và tài nguyên.
-
Sử dụng giao thức copy-on-write: Ban đầu, DB Cluster mới sử dụng cùng một dung lượng lưu trữ dữ liệu với DB Cluster ban đầu, điều này giúp tạo ra một DB Cluster mới mà không cần sao chép dữ liệu, làm cho quá trình tạo ra DB Cluster mới nhanh chóng và hiệu quả.
-
Rất nhanh và tiết kiệm chi phí: Quá trình cloning này rất nhanh chóng và hiệu quả về chi phí, giúp tạo ra các môi trường mới một cách dễ dàng và tiết kiệm.
-
Hữu ích để tạo một cơ sở dữ liệu "staging" từ một cơ sở dữ liệu "production" mà không ảnh hưởng đến cơ sở dữ liệu sản xuất: Tính năng này cho phép phát triển và kiểm thử các tính năng mới hoặc các cập nhật cơ sở dữ liệu mà không làm ảnh hưởng đến cơ sở dữ liệu sản xuất, đảm bảo tính an toàn và ổn định của môi trường sản xuất.
RDS & Aurora Security
-
At-rest encryption: Đây là tính năng mã hóa dữ liệu khi lưu trữ. RDS Aurora hỗ trợ việc mã hóa cả dữ liệu ở trạng thái nghỉ (at-rest) bằng cách sử dụng AWS Key Management Service (KMS). Mã hóa có thể được định nghĩa khi tạo instance và phải được xác định từ thời điểm khởi chạy. Nếu master database không được mã hóa, các read replicas cũng không thể được mã hóa. Để mã hóa một database chưa được mã hóa, bạn có thể sử dụng DB snapshot và khôi phục lại với tùy chọn mã hóa.
-
In-flight encryption: Đây là tính năng mã hóa dữ liệu trong quá trình truyền dữ liệu giữa client và database server. RDS Aurora mặc định sẵn sàng cho việc mã hóa trong quá trình truyền dữ liệu bằng cách sử dụng TLS (Transport Layer Security). Khách hàng có thể sử dụng các chứng chỉ TLS từ AWS root certificates để thiết lập kết nối an toàn.
-
IAM Authentication: Đây là tính năng cho phép sử dụng IAM roles để kết nối đến cơ sở dữ liệu thay vì sử dụng tên người dùng và mật khẩu. IAM Authentication cung cấp một cách tiếp cận an toàn và quản lý quyền truy cập linh hoạt hơn.
-
Security Groups: Đây là tính năng giúp kiểm soát truy cập mạng đến cơ sở dữ liệu RDS / Aurora. Bằng cách cấu hình Security Groups, bạn có thể xác định IP hoặc range IP được phép kết nối đến database.
-
Audit Logs: Đây là tính năng cho phép kích hoạt và gửi các nhật ký kiểm tra (audit logs) đến CloudWatch Logs để lưu trữ lâu dài và giúp quản lý an ninh thông tin.
-
Không có SSH: Trong môi trường RDS Aurora, không có tính năng SSH cho phép truy cập trực tiếp vào instance như trong RDS Custom.
Amazon RDS Proxy
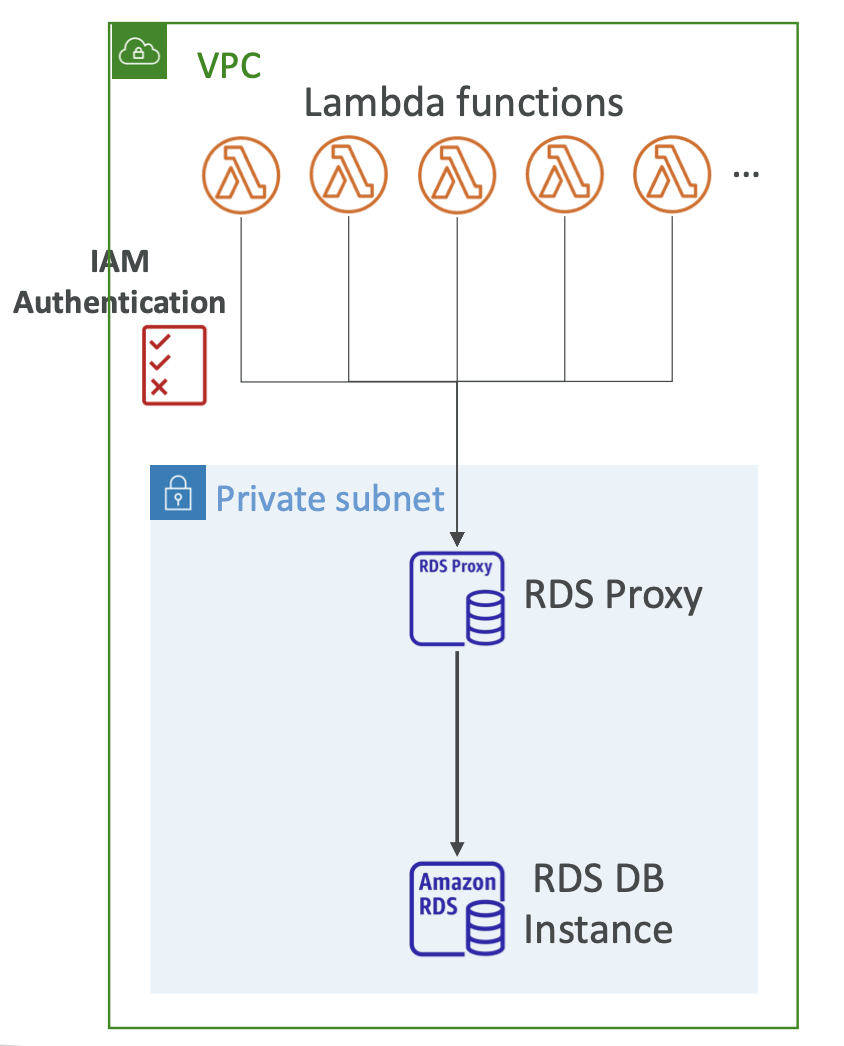
-
Fully Managed Proxy: RDS Proxy là một dịch vụ proxy quản lý đầy đủ cho RDS, giúp quản lý và tối ưu hóa việc kết nối với cơ sở dữ liệu.
-
Connection Pooling and Sharing: Cho phép ứng dụng tạo và chia sẻ các kết nối cơ sở dữ liệu, giúp tăng hiệu suất của cơ sở dữ liệu bằng cách giảm áp lực lên tài nguyên của nó (ví dụ: CPU, RAM) và giảm thiểu các kết nối mở (và thời gian chờ).
-
Serverless, Autoscaling, Highly Available: RDS Proxy hoạt động theo mô hình serverless, tự động co giãn và có khả năng sẵn có cao (multi-AZ), giúp tăng tính sẵn sàng và khả năng mở rộng của ứng dụng.
-
Reduced Failover Time: Giảm thời gian failover của RDS và Aurora lên đến 66%, giúp giảm thiểu ảnh hưởng của các sự cố trên cơ sở dữ liệu đến ứng dụng.
-
Support for Multiple Database Engines: Hỗ trợ các động máy chủ RDS (MySQL, PostgreSQL, MariaDB, MS SQL Server) và Aurora (MySQL, PostgreSQL), giúp tương thích với nhiều loại cơ sở dữ liệu.
-
VPC và IAM Authentication: RDS Proxy chỉ có thể được truy cập từ trong mạng riêng ảo (VPC) và hỗ trợ xác thực IAM cho cơ sở dữ liệu, đảm bảo an toàn và bảo mật thông tin đăng nhập bằng cách lưu trữ chúng trong AWS Secrets Manager.
-
Zero Code Changes Required: Đối với hầu hết các ứng dụng, không cần thay đổi mã nguồn để tích hợp RDS Proxy.
Cluster Volume
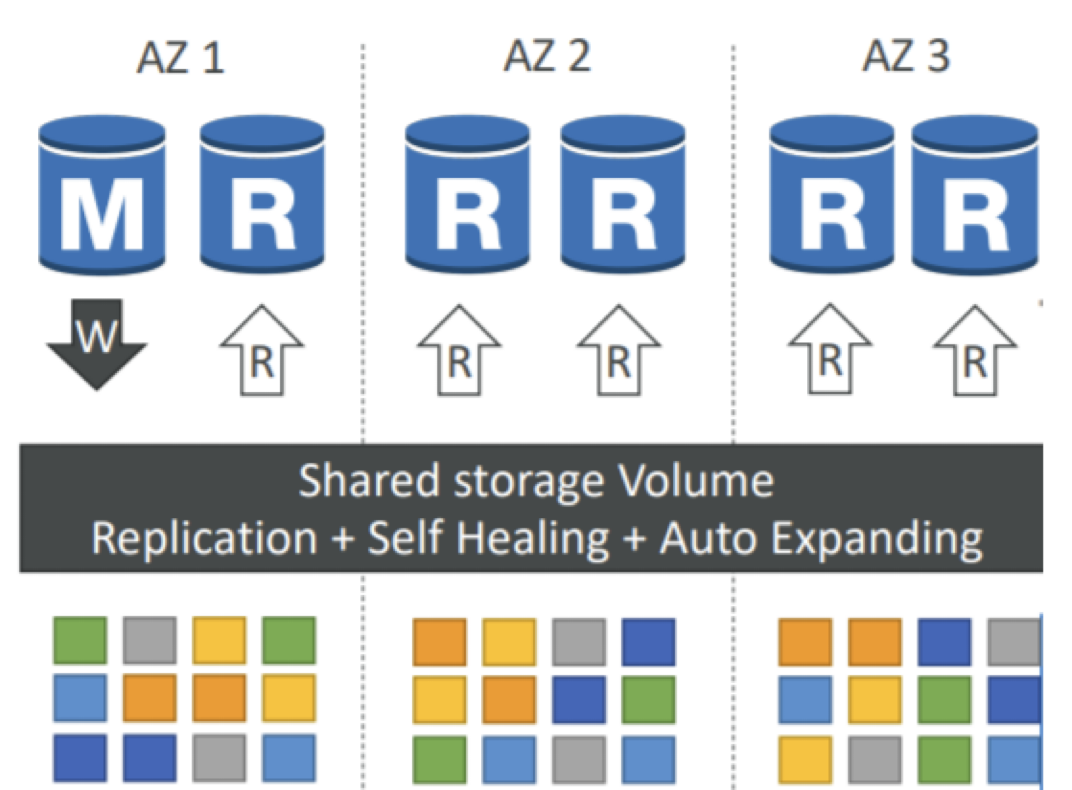
- Cluster Volume: Là một ổ đĩa lưu trữ cơ sở dữ liệu ảo được sử dụng để quản lý dữ liệu cho các DB instances trong Amazon Aurora.
- Striped Storage: Dữ liệu được phân tán trên hàng trăm ổ đĩa lưu trữ.
- Đồng bộ hóa dữ liệu bởi Amazon: Dữ liệu được đồng bộ hóa bởi Amazon ở nhiều khu vực khác nhau để đảm bảo tính toàn vẹn và sẵn sàng.
- Sao lưu dữ liệu trong từng khu vực: Mỗi khu vực sẽ có 2 bản sao của dữ liệu cụm (gần thời gian thực) để đảm bảo sẵn sàng và sao lưu dữ liệu.
- Tự làm mới với sao lưu peer-to-peer replication: Cơ chế tự làm mới với sao lưu peer-to-peer replication cho phép tự động quét lỗi và sửa chữa các ổ đĩa mà gặp phải vấn đề.
Bình luận (0)